

Бизнес-данные часто бывают неполными, противоречивыми или лишенными контекста, что ограничивает их полезность для принятия стратегических решений. Обогащение данных с помощью искусственного интеллекта улучшает исходные данные за счет использования надежных внешних источников, обеспечивая высококачественные наборы данных, которые помогают принимать более эффективные решения в различных отраслях.
В этом руководстве объясняется, что такое обогащение данных с помощью искусственного интеллекта, как оно улучшает традиционные методы, где оно применяется в различных отраслях и как его эффективно внедрить.
Что такое обогащение данных ИИ?
ИИ обогащает данные, полученные от первых лиц, доверенными внешними атрибутами. При этом используется искусственный интеллект (ИИ) для разрешения сущностей (ER), дедупликации и стандартизации схем, что позволяет сократить количество ручных поисков.
Например, отделы продаж обогащают списки компаний сведениями о руководстве (генеральный директор, учредители), обновленной информацией о финансировании, технографическими данными и проверенными контактами. Финансовые отделы объединяют профили клиентов с атрибутами кредитных бюро и шаблонами транзакций. Это готовые к принятию решений данные для более четкой сегментации, более разумной маршрутизации, более надежного скоринга в продажах и более тщательной оценки рисков в финансах.
Расширяя охват и улучшая качество характеристик, обогащение также укрепляет последующие модели, уменьшая классические эффекты “мусор вошел, мусор вышел” при наличии рационального управления данными, проверки на предвзятость и постоянного мониторинга.
Как ИИ улучшает традиционное обогащение данных
Традиционное обогащение данных в значительной степени опиралось на ручные исследования, таблицы поиска, формулы электронных таблиц или базовые сценарии ETL, которые отнимали много времени, были подвержены ошибкам и с трудом масштабировались. Хотя некоторые автоматизированные инструменты обеспечивали частичную масштабируемость, им не хватало адаптации к различным источникам данных. ИИ преобразует этот процесс, используя передовые технологии для более быстрого, точного и масштабируемого обогащения:
- Распознавание образов и ранжирование источников. Модели машинного обучения (ML) выявляют закономерности для замены отсутствующих полей (например, предсказывают названия должностей на основе похожих записей) и ранжируют источники данных по охвату, точности и свежести. Например, ML может отдать предпочтение проверенному профилю LinkedIn перед устаревшей базой данных.
- Обработка неструктурированных текстов. Обработка естественного языка (NLP) и распознавание именованных сущностей (NER) позволяют извлекать сущности (например, имена, организации), темы, настроения и сигналы о покупке из неструктурированных источников, таких как социальные сети или веб-сайты компаний.
- Понимание документов. Оптическое распознавание символов (OCR) и анализ макета преобразуют такие документы, как счета-фактуры, контракты и формы, в структурированные поля. Интеллектуальная обработка документов (IDP) на основе ИИ определяет сложные макеты, такие как таблицы или многоколоночные форматы.
- Синхронизация и свежесть. ИИ координирует работу нескольких API и наборов данных, используя механизмы резервного копирования, дедупликации и проверки для обеспечения свежести данных в режиме реального времени.
Эти методы обеспечивают более быстрое и точное обогащение, нормализацию полей в соответствии с чистой схемой и поддержание свежести данных в режиме реального времени без хрупких наборов правил.
Обратите внимание – современное обогащение объединяет извлечение на основе LLM с классическим управлением основными данными / извлечением-загрузкой-трансформацией (MDM/ELT). Команды получают доверенные внешние данные (рыночные площадки + веб-скраппинг), превращают их в структурированные поля с помощью LLM, преобразуют сущности в единую золотую запись, обеспечивают проверку качества данных и предоставляют результаты через хранилище данных и векторную базу данных + генерацию с расширением поиска (RAG) – сквозное измерение с оценкой и возможностью наблюдения.
Примеры использования в разных отраслях
Обогащение данных с помощью ИИ приносит пользу практически во всех отраслях. Вот основные области применения:
- Маркетинг и продажи. Обогащение клиентских профилей демографическими, фирменными и поведенческими данными (например, названиями должностей, историей покупок, активностью в социальных сетях) для уточнения сегментации, улучшения скоринга лидов и персонализации рекомендаций.
- Финансовые услуги. Интеграция истории транзакций с внешними сигналами (например, новостями, публичными документами, данными об альтернативных кредитах) для улучшения оценки рисков, выявления мошенничества и моделей AML, а также для адаптации ответственных кредитных предложений.
- Здравоохранение. Объединение данных EHR с деидентифицированными данными о населении и образе жизни для прогнозирования повторных госпитализаций и персонализации лечения.
- Розничная торговля и электронная коммерция. Объединение данных POS и каталога с внешними факторами (например, погодой, ценами конкурентов) для оптимизации прогнозирования спроса, управления запасами и сокращения складских запасов.
Практическая реализация – создание системы обогащения ИИ
Вот как построить систему обогащения данных о компаниях, которая обрабатывает список названий компаний (набранных или загруженных в формате CSV) для получения комплексной бизнес-аналитики.
Вам понадобятся 3 основных компонента:
- Веб-интерфейс. Простой фронт-энд с использованием Streamlit, позволяющий пользователям вводить названия компаний или загружать CSV-файлы.
- Сбор данных. API Web Scraper от Bright Data для сбора публичных данных из Интернета в режиме реального времени.
- ИИ-обработка. Большая языковая модель (LLM), например Google Gemini, для анализа необработанных страниц и извлечения структурированных полей (например, генеральный директор, штаб-квартира, последние новости, раунды финансирования).
Как это работает
Вот схема работы:
- Проверка ввода. Принимаем названия компаний через текстовый ввод или загрузку CSV в Streamlit.
- Сбор данных. Используйте API Web Scraper от Bright Data для сбора публичных данных по каждой компании.
- Извлечение искусственного интеллекта. Нормализуйте текст страницы, а затем попросите Gemini вернуть строгий объект JSON, соответствующий вашей схеме.
- Обработка данных. Очистка и проверка выходных данных JSON.
- Экспорт. Отображение результатов в Streamlit в виде интерактивной таблицы с такими опциями, как сортировка, фильтрация и загрузка.
Ознакомьтесь с полным кодом в репо AI Company Enrichment – выполните шаги по настройке, чтобы запустить его локально. Вот пример интерфейса:
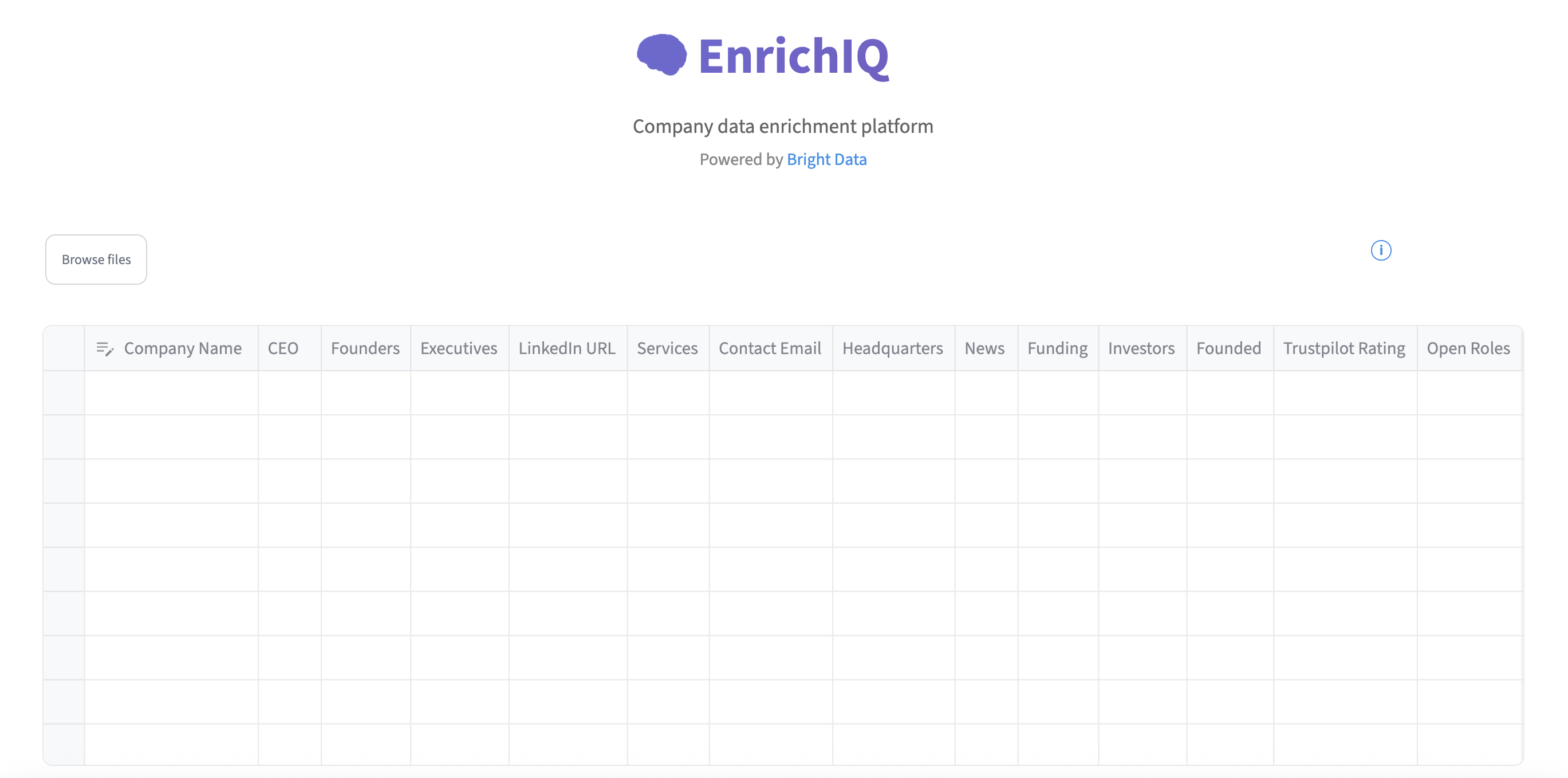
Вы готовы к работе!
Проблемы и лучшие практики
Эффективное обогащение данных с помощью ИИ требует тщательного планирования для решения основных проблем:
- Проблемы с качеством данных. Непоследовательные, неполные или необъективные данные могут подорвать модели ИИ, что приведет к ненадежным прогнозам. Плохое управление усугубляет эти риски. Очистка и проверка данных перед обогащением очень важны для обеспечения точности и справедливости.
- Проблемы интеграции. Многие проекты в области ИИ терпят неудачу из-за трудностей интеграции обогащенных данных с существующими системами, которые часто вызваны несовместимостью форматов или разрозненностью инфраструктуры. Бесперебойные рабочие процессы требуют надежных инструментов и планирования.
- Требования к соответствию. Такие нормативные акты, как GDPR, требуют наличия законных оснований, ограничения целей и определенных сроков хранения, в то время как CCPA/CPRA делают акцент на минимизации и прозрачности данных. Несоблюдение этих требований чревато штрафами и репутационным ущербом.
- Надежность инфраструктуры. Для обеспечения бесперебойной работы ИИ конвейеры данных должны поддерживать высокую работоспособность и управлять лимитами использования. Простои или узкие места могут нарушить процесс обучения и развертывания моделей. Платформа Bright Data обеспечивает 99,99 % бесперебойной работы сети для бесперебойного потока данных.
Лучшие практики
- Выбирайте надежную, соответствующую требованиям инфраструктуру. Выбирайте платформы с проверенным временем безотказной работы (в идеале – 99,9 % или выше) и соответствующие таким нормативным требованиям, как GDPR и CCPA. Оцените несколько провайдеров, исходя из специфики использования, например объема данных или особых потребностей ИИ, и убедитесь в этичности их практики поиска данных.
- Внедрите валидацию и обнаружение аномалий. Используйте автоматизированные инструменты для проверки несоответствий, дубликатов и выбросов перед обогащением. Это гарантирует высокое качество исходных данных и снижает количество ошибок в моделях ИИ.
- Ведите подробную документацию. Документируйте источники данных, их назначение и политику хранения, чтобы обеспечить прослеживаемость и соответствие требованиям. Это необходимо для проведения аудита и повышения доверия к системам ИИ.
- Используйте различные источники данных. Изучите авторитетные рынки данных или готовые наборы данных, чтобы упростить процесс обогащения. Сравните поставщиков по качеству, стоимости и соответствию целям ИИ и рассмотрите возможность сбора данных на заказ, если готовые варианты не удовлетворяют требованиям.
Заключение
Обогащение данных с помощью ИИ превращает необработанные данные в конкурентное преимущество, способствующее принятию более разумных решений, повышению качества обслуживания клиентов и росту доходов. Решая такие проблемы, как качество данных, интеграция, соответствие требованиям и инфраструктура, организации раскрывают весь потенциал ИИ. Bright Data поддерживает этот путь с помощью надежной инфраструктуры и высококачественных наборов данных, позволяя вам сосредоточиться на анализе.
Следующие шаги
Чтобы освоить обогащение данных ИИ, воспользуйтесь мощными инструментами и поддержкой Bright Data:
- Усильте свои модели ИИ с помощью передовых API-интерфейсов веб-доступа для беспрепятственного доступа к данным.
- Изучите лучший инструмент MCP для подключения вашего ИИ к Интернету и получайте 5 000 запросов MCP каждый месяц бесплатно.
- Используйте предварительно собранные наборы данных с миллиардами записей для получения высококачественных данных.
- Интеграция с платформами ИИ, такими как n8n и CrewAI, для подключения и создания агентов ИИ.
- Узнайте больше о решениях в области данных ИИ на странице блогов Bright Data.
Чтобы получить квалифицированную консультацию, обратитесь в службу поддержки Bright Data.





