
Веб-скрепинг играет важную роль в масштабном сборе данных, особенно когда необходимо быстро принимать обоснованные решения.
В этом уроке вы узнаете:
- Что такое Midscene.js и как он работает,
- Ограничения при использовании Midscene.js,
- Как Bright Data помогает преодолеть эти трудности
- Как интегрировать Midscene.js с Bright Data для эффективного веб-скреппинга
Давайте погрузимся!
Что такое Midscene.js?
Midscene.js – это инструмент с открытым исходным кодом, позволяющий автоматизировать взаимодействие с браузером с помощью простого английского языка. Вместо того чтобы писать сложные скрипты, вы можете просто набирать команды вроде “Нажмите кнопку входа” или “Введите в поле электронной почты”. Затем Midscene преобразует эти команды в шаги автоматизации с помощью агентов искусственного интеллекта.
Он также поддерживает современные инструменты автоматизации браузера, такие как Puppeteer и Playwright, что делает его особенно полезным для таких задач, как тестирование, автоматизация пользовательского интерфейса и создание динамических веб-сайтов.
В деталях, основные функции, которые он предлагает, таковы:
- Управление на естественном языке: Автоматизируйте задачи, используя понятные подсказки на английском языке, а не код.
- Интеграция искусственного интеллекта с сервером MCP: Подключение к моделям искусственного интеллекта через сервер MCP для создания сценариев автоматизации.
- Встроенная поддержка Puppeteer и Playwright: Выступает в качестве высокоуровневого слоя над популярными фреймворками, облегчая управление и расширение рабочих процессов.
- Кроссплатформенная автоматизация: Поддерживает как веб (через Puppeteer/Playwright), так и Android (через JavaScript SDK).
- Опыт работы без кода: Предлагает такие инструменты, как расширение Midscene Chrome Extension, позволяющее создавать автоматизированные системы без написания строк кода.
- Простой дизайн API: Предоставляет чистый, хорошо документированный API для взаимодействия с элементами страницы и эффективного извлечения контента.
Ограничения использования Midscene для автоматизации веб-браузера
Midscene использует модели искусственного интеллекта, такие как GPT-4o или Qwen, для автоматизации браузеров с помощью команд на естественном языке. Она работает с такими инструментами, как Puppeteer и Playwright, но имеет ключевые ограничения.
Точность Midscene зависит от четкости ваших инструкций и структуры страницы. Расплывчатые подсказки вроде “нажмите кнопку” могут не сработать, если есть несколько похожих кнопок. ИИ опирается на скриншоты и визуальные макеты, поэтому небольшие структурные изменения или отсутствие надписей могут привести к ошибкам или неправильным нажатиям. Подсказки, сработавшие на одной веб-странице, могут не сработать на другой, имеющей схожий внешний вид.
Чтобы свести к минимуму количество ошибок, пишите четкие, конкретные инструкции, соответствующие структуре страницы. Всегда тестируйте подсказки с помощью расширения Midscene Chrome Extension, прежде чем интегрировать их в сценарии автоматизации.
Еще одно ключевое ограничение – высокое потребление ресурсов. Каждый шаг автоматизации с помощью Midscene отправляет снимок экрана и запрос модели искусственного интеллекта, используя множество токенов – особенно на динамических страницах или страницах с большим объемом данных. Это может привести к ограничению скорости работы AI API и повышению стоимости использования при увеличении количества автоматизированных шагов.
Midscene также не может взаимодействовать с защищенными элементами браузера, такими как CAPTCHA, кросс-оригинальные iframes или контент за стенами аутентификации. Как следствие, скраппинг защищенного или закрытого контента невозможен. Midscene наиболее эффективен на статичных или умеренно динамичных сайтах с доступным, структурированным контентом.
Почему яркие данные – более эффективное решение
Bright Data – это мощная платформа для сбора данных, которая поможет вам создавать, запускать и масштабировать операции по сбору данных с веб-сайтов. Она предлагает мощную прокси-инфраструктуру, инструменты автоматизации и наборы данных для предприятий и разработчиков, позволяя вам получать доступ, извлекать и взаимодействовать с любыми публичными веб-сайтами.
- Работа с динамическими и JavaScript-тяжелыми веб-сайтами Bright Data предлагает различные инструменты, такие как SERP API, Crawl API, Browser API и Unlocker API, которые позволяют вам получать доступ, извлекать данные и взаимодействовать со сложными веб-сайтами, которые загружают контент динамически. Эти инструменты позволяют извлекать данные с любой платформы, что делает их идеальными для электронной коммерции, путешествий и платформ недвижимости.
- Эффективная инфраструктура прокси Bright Data предлагает мощную и гибкую инфраструктуру прокси через свои четыре основные сети: Жилая, ЦОД, ISP и Мобильная. Эти сети обеспечивают доступ к миллионам IP-адресов по всему миру, позволяя пользователям надежно собирать веб-данные и минимизировать блокировки.
- Поддержка мультимедийного контента Bright Data позволяет извлекать различные типы контента, включая видео, изображения, аудио и текст, из общедоступных источников. Его инфраструктура разработана для работы с крупномасштабными коллекциями мультимедиа и поддержки передовых сценариев использования, таких как обучение моделей компьютерного зрения, создание инструментов распознавания речи и обеспечение работы систем обработки естественного языка.
- Предоставление готовых наборов данных Bright Data предоставляет готовые наборы данных, полностью структурированные, высококачественные и готовые к использованию. Эти наборы данных охватывают различные сферы, включая электронную коммерцию, размещение вакансий, недвижимость и социальные сети, что делает их подходящими для различных отраслей и случаев использования.
Как интегрировать Midscene.js с Bright Data
В этом учебном разделе вы узнаете, как соскребать данные с веб-сайтов с помощью Midscene и Browser API Bright Data, а также как объединить оба инструмента для улучшения функциональности веб-скреппинга.
Чтобы продемонстрировать это, мы возьмем статичную веб-страницу, на которой отображается список контактных карточек сотрудников. Мы начнем с использования Midscene и Bright Data по отдельности, а затем интегрируем их с помощью Puppeteer, чтобы показать, как они могут работать вместе.
Пререквизиты
Чтобы следовать этому руководству, убедитесь, что у вас есть следующее:
- Учетная запись Bright Data.
- редактор кода, например, Visual Studio Code, Cursor и т.д.
- Ключ API OpenAI, поддерживающий модель GPT-4o.
- Базовые знания языка программирования JavaScript.
Если у вас еще нет учетной записи Bright Data, не волнуйтесь. Мы расскажем вам о том, как их создать, в следующих шагах.
Шаг №1: Настройка проекта
Откройте терминал и выполните следующую команду, чтобы создать новую папку для скриптов автоматизации:
mkdir automation-scripts
cd automation-scripts
Добавьте файл package.json во вновь созданную папку с помощью следующего фрагмента кода:
npm init -y
Измените значение типа package.json с commonjs на module.
{
"type": "module"
}
Далее установите необходимые пакеты, чтобы включить выполнение TypeScript и получить доступ к функциональности Midscene.js:
npm install tsx @midscene/web --save
Затем установите пакеты Puppeteer и Dotenv.
npm install puppeteer dotenv
Puppeteer – это библиотека Node.js, которая предоставляет высокоуровневый API для управления браузерами Chrome или Chromium. Dotenv позволяет безопасно хранить ключи API.
Теперь все необходимые пакеты установлены. Мы можем приступить к написанию сценариев автоматизации.
Шаг № 2: Автоматизация веб-скрапинга с помощью Midscene.js
Прежде чем мы продолжим, создайте файл .env в папке automation-scripts и скопируйте в него ключ API OpenAI в качестве переменной окружения.
OPENAI_API_KEY=<your_openai_key>
Midscene использует модель OpenAI GPT-4o для выполнения задач автоматизации по командам пользователя.
Затем создайте файл в этой папке.
cd automation-scripts
touch midscene.ts
Импортируйте Puppeteer, Midscene Puppeteer Agent и конфигурацию dotenv в этот файл:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
Добавьте следующий фрагмент кода в файл midscene.ts:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
Этот фрагмент кода инициализирует Puppeteer внутри асинхронного Immediately Invoked Function Expression (IIFE). Такая структура позволяет использовать await на верхнем уровне, не оборачивая логику в несколько вызовов функций.
Затем добавьте следующие фрагменты кода в IIFE:
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
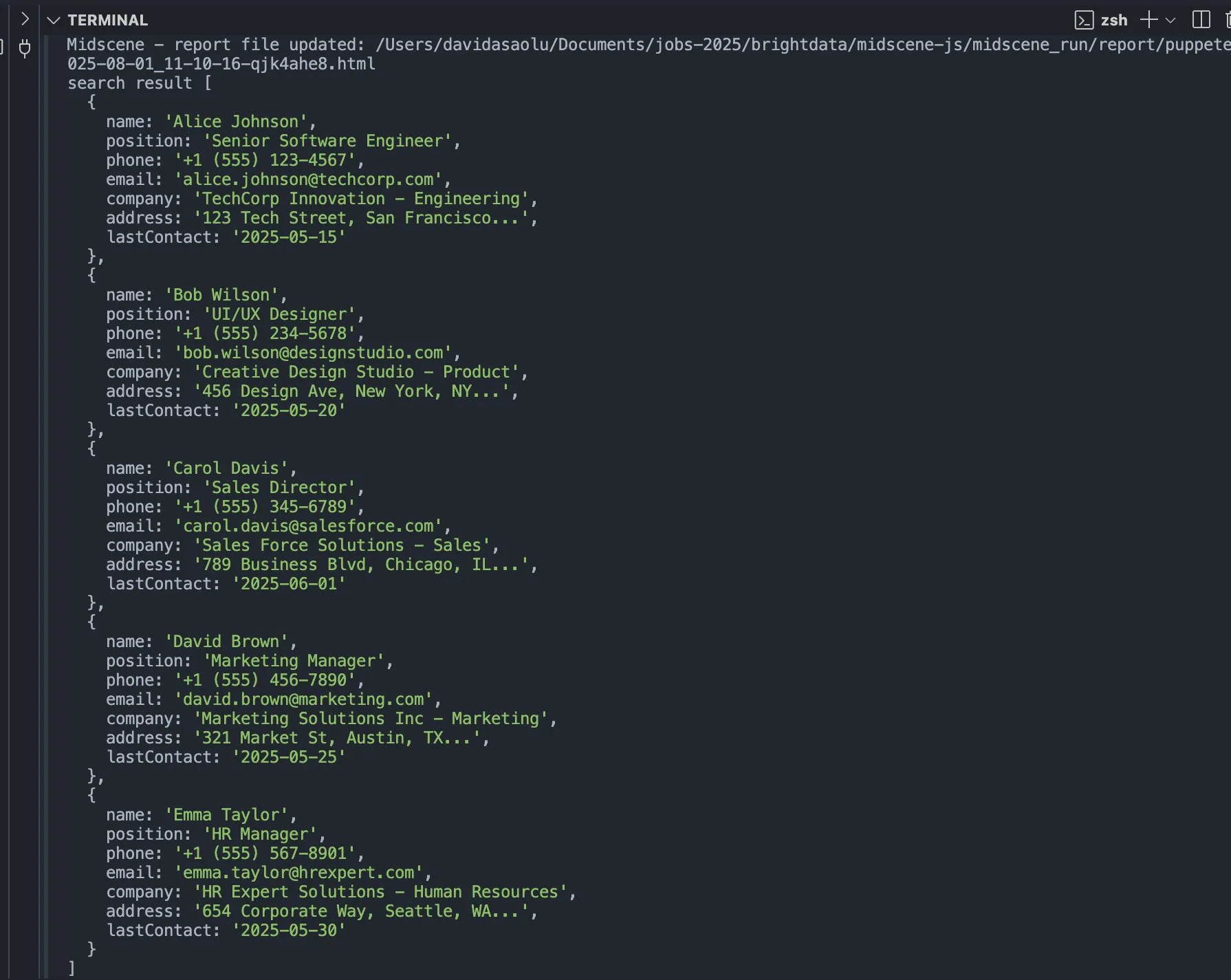
console.log("search result", items);
Приведенный выше фрагмент кода переходит по адресу веб-страницы, инициализирует агента Puppeteer, извлекает все контактные данные с веб-страницы и регистрирует результат.
Шаг № 3: Автоматизация веб-скрапинга с помощью Bright Data Browser API
Создайте файл brightdata.ts в папке automation-scripts.
cd automation-scripts
touch brightdata.ts
Перейдите на главную страницу Bright Data и создайте учетную запись.
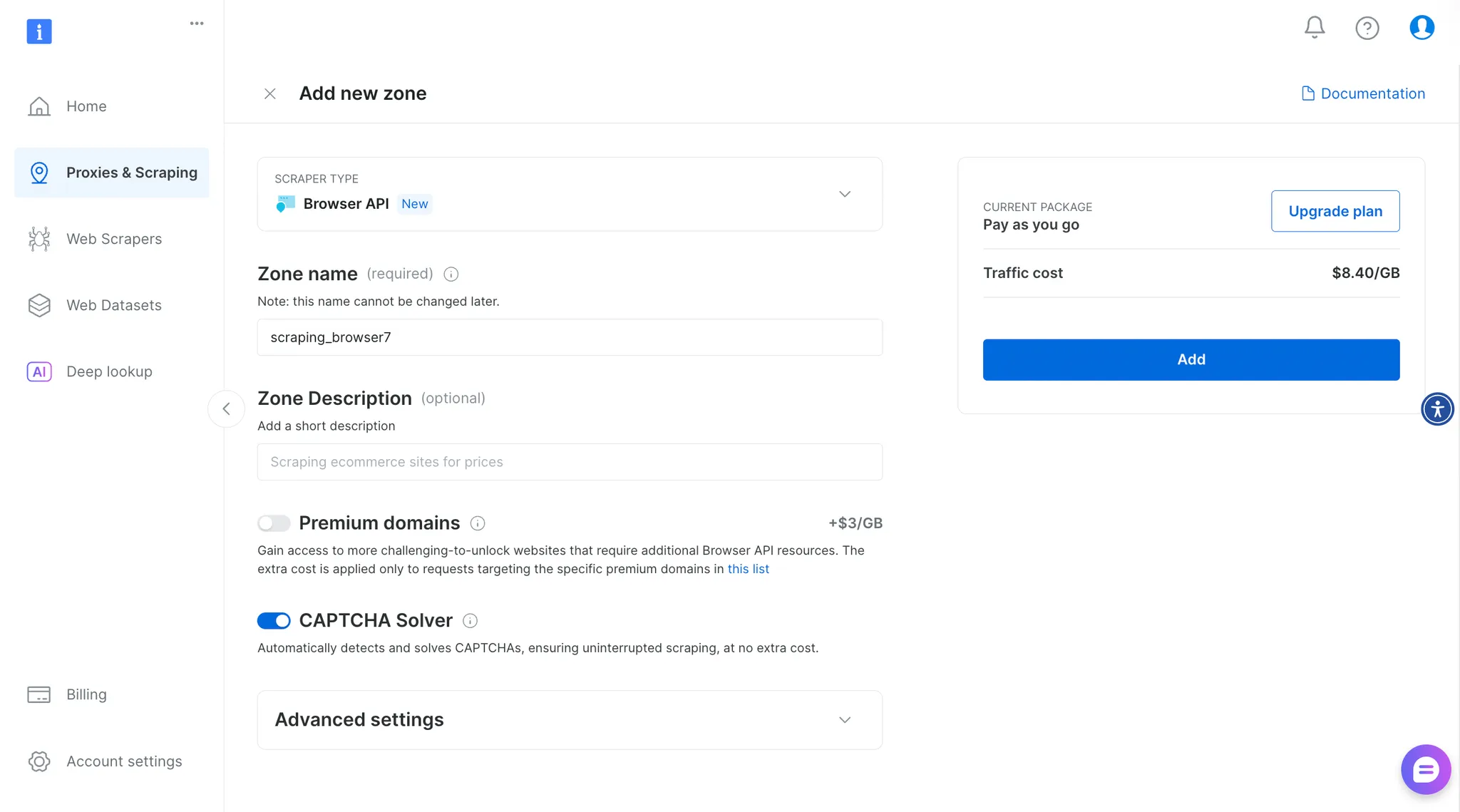
Выберите Browser API на панели управления, затем введите имя и описание зоны, чтобы создать новый API браузера.
Затем скопируйте учетные данные Puppeteer и сохраните их в файле brightdata.ts, как показано ниже:
const BROWSER_WS = "wss://brd-customer-******";
Измените файл brightdata.ts, как показано ниже:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
В этом фрагменте кода объявляется переменная для URL-адреса веб-страницы и учетной записи API браузера Bright Data, а затем объявляется функция, принимающая URL-адрес в качестве параметра.
Добавьте следующий фрагмент кода в местодержатель рабочего процесса веб-автоматизации:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
Приведенный ниже фрагмент кода подключает Puppeteer к Bright Data Browser с помощью конечной точки API WebSocket. После установления соединения открывается новая страница браузера и осуществляется переход на URL, переданный в функцию run().
И наконец, получите данные на веб-странице с помощью селекторов CSS с помощью следующего фрагмента кода:
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
Приведенный выше фрагмент кода просматривает каждую карточку контакта на веб-странице и извлекает такие ключевые данные, как имя, должность, номер телефона, адрес электронной почты, компания, адрес и дата последнего контакта.
Вот полный сценарий автоматизации:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
Шаг № 4: Сценарии автоматизации ИИ с помощью Midscene и Bright Data
Bright Data поддерживает веб-автоматизацию с помощью агентов искусственного интеллекта благодаря интеграции с Midscene. Поскольку оба инструмента поддерживают Puppeteer, их объединение позволяет писать простые рабочие процессы автоматизации на основе ИИ. Создайте файл combine.ts и скопируйте в него следующий фрагмент кода:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);
Приведенный выше фрагмент кода создает асинхронный IIFE (Immediately Invoked Function Expression) и включает функцию sleep, которая позволяет добавлять задержки в сценарий автоматизации ИИ.
Затем добавьте следующий фрагмент кода в держатель рабочего процесса веб-автоматизации:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
Этот фрагмент кода инициализирует Puppeteer и его агента для перехода на веб-страницу, получения всех контактных данных и записи результатов в консоль. Это показывает, как можно интегрировать агент искусственного интеллекта Puppeteer с Bright Data Browser API, чтобы полагаться на понятные команды, которые предоставляет Midscene.
Шаг №5: Собираем все вместе
В предыдущем разделе вы узнали, как интегрировать Midscene с Bright Data Browser API. Полный сценарий автоматизации показан ниже:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);
Запустите следующий фрагмент кода в терминале, чтобы выполнить скрипт:
npx tsx combine.ts
Приведенный выше фрагмент кода выполняет сценарий автоматизации и записывает данные о контакте в консоль.
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2025-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2025-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2025-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2025-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2025-05-30'
}
]
Шаг № 6: Следующие шаги
Этот учебник показывает, что возможно при интеграции Midscene с API Bright Data Browser. На этой основе можно автоматизировать более сложные рабочие процессы.
Объединив оба инструмента, вы сможете выполнять эффективные и масштабируемые задачи автоматизации браузера, такие как:
- Соскабливание структурированных данных с динамических или насыщенных JavaScript веб-сайтов
- Автоматизация отправки форм для тестирования или сбора данных
- Навигация по веб-сайтам и взаимодействие с элементами с помощью инструкций на естественном языке
- Выполнение масштабных заданий по извлечению данных с управлением прокси-серверами и обработкой CAPTCHA
Заключение
До сих пор вы узнали, как автоматизировать процессы веб-скрапинга с помощью Midscene и Bright Data Browser API, а также как использовать оба инструмента для скрэпинга веб-сайтов с помощью агентов искусственного интеллекта.
Midscene в значительной степени зависит от моделей искусственного интеллекта для автоматизации браузера, а использование его вместе с Bright Data Scraping Browser означает сокращение количества строк кода при эффективных функциях веб-скрепинга. Browser API – это лишь один из примеров того, как инструменты и сервисы Bright Data могут расширить возможности автоматизации на основе искусственного интеллекта.
Подпишитесь сейчас, чтобы узнать обо всех продуктах.





