

Из этого руководства вы узнаете, как создать скрипт Python для парсинга раздела Google «Люди также спрашивают». Сюда входят часто задаваемые вопросы, связанные с вашим поисковым запросом, и ценная информация.
Давайте рассмотрим эти вопросы подробнее!
Понимание функции Google «Люди также спрашивают»
«Люди также задают” (PAA) — это раздел в поисковой выдаче Google (страницы результатов поисковой системы), в котором представлен динамический список вопросов, связанных с поисковым запросом:

Этот раздел поможет вам глубже изучить темы, связанные с вашим поисковым запросом. PAA, впервые запущенный примерно в 2015 году, отображается в результатах поиска в виде серии расширяемых вопросов. При нажатии на вопрос появляется краткий ответ, полученный с соответствующей веб-страницы, а также ссылка на источник:

Раздел «Люди также спрашивают» часто обновляется и адаптируется к поисковым запросам пользователей, предлагая свежую и актуальную информацию. Новые вопросы динамически загружаются по мере открытия выпадающих списков.
Парсинг «Люди также спрашивают» Google: пошаговое руководство
Выполняйте инструкции в этом разделе и узнайте, как создать скрипт Python, позволяющий парсить поисковую выдачу Google «Люди также спрашивают».
Конечная цель — получить данные, содержащиеся в каждом вопросе в разделе «Люди также спрашивают» на странице. Если вы вместо этого заинтересованы в парсинге Google, следуйте нашему руководству по парсингу поисковой выдачи (SERP).
Шаг 1. Настройка проекта
Перед началом работы убедитесь, что на вашем компьютере установлен Python 3. В противном случае скачайте его, запустите исполняемый файл и следуйте указаниям мастера установки.
Затем используйте команды ниже, чтобы инициализировать проект Python с виртуальной средой:
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
Папка people-also-ask-scraper представляет собой папку проекта вашего парсера Python PAA.
Загрузите папку проекта в свою любимую Python IDE. PyCharm Community Edition или Visual Studio Code с расширением Python — это два отличных варианта.
В папке проекта создайте файл scraper.py. Теперь это пустой скрипт, но скоро он будет содержать логику парсинга:

В терминале IDE активируйте виртуальную среду. В Linux или macOS выполните следующую команду:
./env/bin/activate
Или же в Windows запустите:
env/Scripts/activate
Отлично, теперь у вас есть среда Python для вашего парсера!
Шаг 2. Установка Selenium
Google — это платформа, которая требует взаимодействия с пользователем. Кроме того, подделать правильный URL-адрес для поиска в Google может быть непросто. Таким образом, лучше всего работать с поисковой системой в браузере.
Другими словами, чтобы парсить раздел «Люди также спрашивают», вам нужен инструмент автоматизации браузера. Если вы не знакомы с этой концепцией, инструменты автоматизации браузера позволяют отображать веб-страницы и взаимодействовать с ними в управляемом браузере. Один из лучших вариантов в Python — Selenium!
Установите Selenium, выполнив следующую команду в активированной виртуальной среде Python:
pip install selenium
Пакет selenium pip будет добавлен в зависимости вашего проекта. Это может занять некоторое время, поэтому наберитесь терпения.
Подробнее об использовании этого инструмента читайте в нашем руководстве по парсингу веб-страниц с помощью Selenium.
Замечательно, теперь у вас есть все необходимое, чтобы начать парсить страницы Google!
Шаг 3: перейдите на домашнюю страницу Google
Импортируйте Selenium в scraper.py и инициализируйте объект WebDriver для управления экземпляром Chrome в автономном режиме:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
Приведенный выше фрагмент создает инстанс Chrome WebDriver , объект для программного управления окном Chrome. Опция --headless настраивает Chrome на работу в режиме без заголовка. Для отладки закомментируйте эту строку, чтобы вы могли наблюдать за действиями автоматизированного скрипта в реальном времени.
Затем используйте метод get () для подключения к домашней странице Google:
driver.get("https://google.com/")
Не забудьте освободить ресурсы драйвера в конце скрипта:
driver.quit()
Соберите все это вместе, и вы получите:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
Отлично, вы готовы парсить динамические веб-сайты!
Шаг 4. Разберитесь с диалоговым окном GDPR по использованию файлов cookie
Примечание: Если вы не находитесь в ЕС (Европейском союзе), вы можете пропустить этот шаг.
Запустите скрипт scraper.py в headed-режиме. Это ненадолго откроет окно браузера Chrome со страницей Google, а затем команда quit () закроет его. Если вы находитесь в ЕС, вот что вы увидите:
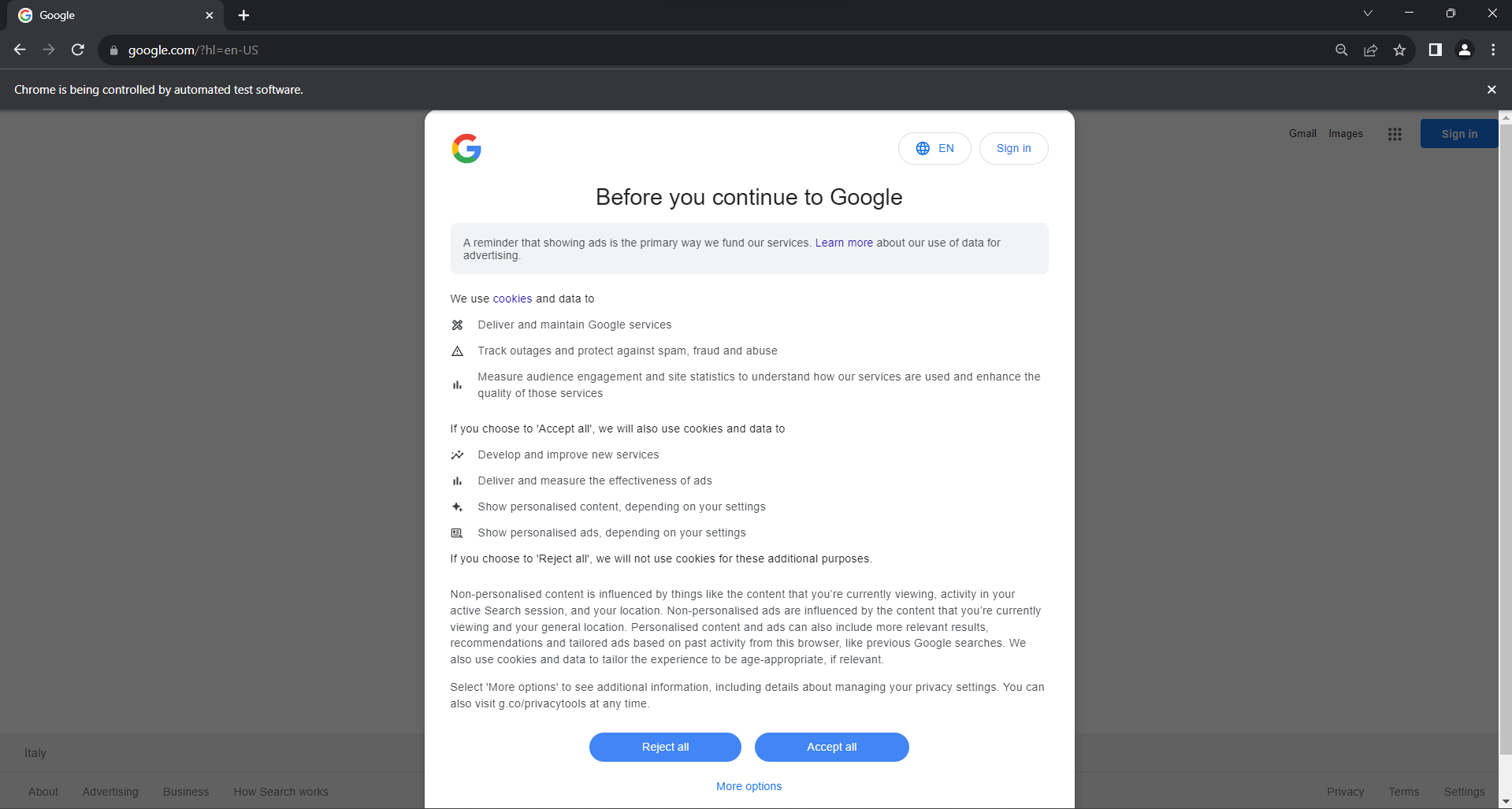
«Chrome контролируется программным обеспечением для автоматического тестирования». Это сообщение подтверждает, что Selenium контролирует Chrome, как и нужно.
Пользователям из ЕС отображается диалоговое окно с политикой использования файлов cookie по причинам GDPR. Если это ваш случай, вам необходимо разобраться с этим, если вы хотите взаимодействовать с базовой страницей. В противном случае вы можете перейти к шагу 5.
Откройте страницу Google в режиме инкогнито и просмотрите код диалогового окна файлов cookie GDPR. Щелкните по нему правой кнопкой мыши и выберите опцию «Просмотреть код»:

Обратите внимание, что HTML-элемент диалогового окна можно найти с помощью:
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element () — это метод, предоставляемый Selenium для поиска HTML-элементов на странице с помощью различных стратегий. В данном случае мы использовали селектор CSS .
Не забудьте импортировать By следующим образом:
from selenium.webdriver.common.by import By
Теперь сосредоточьтесь на кнопке «Принять все»:

Как вы видите, выбрать его непросто, так как его класс CSS, похоже, генерируется случайным образом. Таким образом, вы можете получить его с помощью выражения XPath, предназначенного для его содержимого:
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
Эта инструкция найдет первую кнопку в диалоговом окне, текст которой содержит строку «Принять». Для получения дополнительной информации ознакомьтесь с нашим руководством по XPath и селектору CSS.
Вот как все работает с дополнительным диалоговым окном Google cookie:
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
Инструкция click () нажимает кнопку «Принять все», чтобы закрыть диалоговое окно и разрешить взаимодействие с пользователем. Если диалоговое окно политики использования файлов cookie отсутствует, вместо этого будет создано исключение NosuchelementException. Скрипт поймает его и продолжит.
Не забудьте импортировать NoSuchelementException:
from selenium.common import NoSuchElementException
Отлично! Вы готовы перейти на страницу с разделом «Люди также спрашивают».
Шаг 5: отправьте форму поиска
Перейдите на домашнюю страницу Google в своем браузере и просмотрите код формы поиска. Щелкните по нему правой кнопкой мыши и выберите опцию «Просмотреть код»:

У этого элемента нет класса CSS, но вы можете выбрать его с помощью атрибута action:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
Если вы пропустили шаг 4, импортируйте By с помощью:
from selenium.webdriver.common.by import By
Разверните HTML-код формы и взгляните на текстовое поле поиска:

Кажется, что класс CSS этого узла сгенерирован случайным образом. Таким образом, выберите его с помощью атрибута aria-label. Затем используйте метод send_keys() для ввода целевого поискового запроса:
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
В этом примере используется поисковый запрос «Bright Data», но подойдет любой другой поиск.
Отправьте форму, чтобы инициировать изменение страницы:
search_form.submit()
Великолепно! Теперь контролируемый браузер будет перенаправлен на страницу Google, содержащую раздел «Люди также спрашивают».
Если вы выполняете скрипт в headed-режиме, перед закрытием браузера вы должны увидеть следующее:
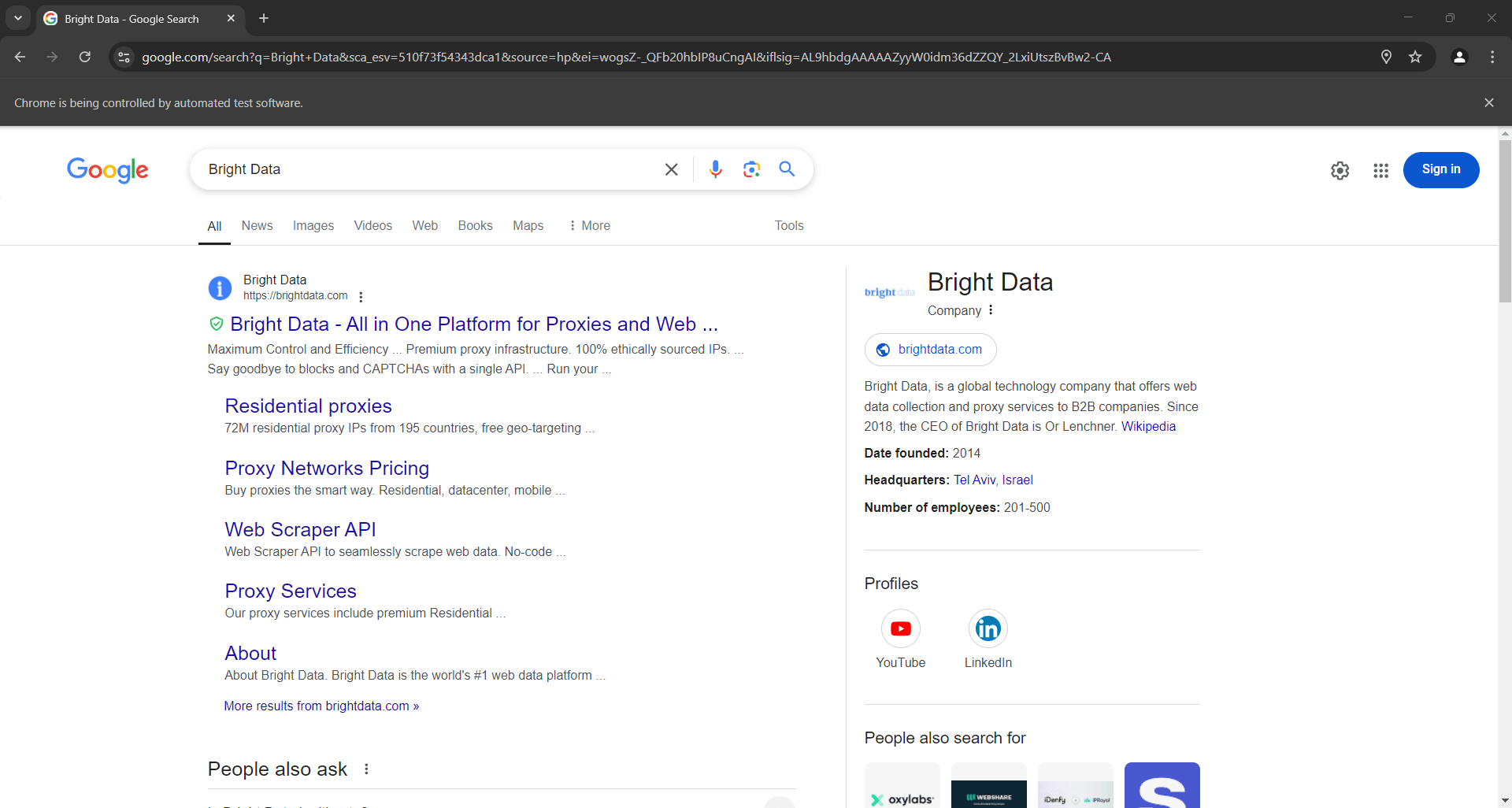
Обратите внимание на раздел «Люди также спрашивают» в нижней части скриншота выше.
Шаг 6: выберите узел «Люди также спрашивают»
Просмотр кода HTML-элемента «Люди также спрашивают»:

Опять же, нет простого способа выбрать его. На этот раз вы можете получить элемент <div> с атрибутами jscontroller, jsname и jsaction , который содержит div с role=heading текстом «Люди также спрашивают»:
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
WebDriverWait — это специальный класс Selenium, который приостанавливает выполнение скрипта до тех пор, пока на странице не будет выполнено определенное условие. Выше показано, что требуемый HTML-элемент ожидает появления нужного HTML-элемента до 5 секунд. Это необходимо для полной загрузки страницы после отправки формы.
Выражение XPath, используемое в presence_of_element_located(), сложное, но точно описывает критерии, необходимые для выбора элемента «Люди также спрашивают».
Не забудьте добавить необходимый импорт:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Пора начать парсить данные из раздела Google «Люди также спрашивают»!
Шаг 7. Парсинг «Люди также спрашивают»
Во-первых, инициализируйте структуру данных, в которой будет храниться информация, полученная в ходе парсинга:
people_also_ask_questions = []
Это должен быть массив, так как в разделе «Люди также спрашивают» содержится несколько вопросов.
Теперь просмотрите код раскрывающегося списка первого вопроса в узле «Люди также спрашивают»:

Здесь видно, что интересующие элементы являются дочерними элементами data-sgrd="true" <div> в элементе «Люди также спрашивают» и содержат только атрибут jsname. Последние два дочерних элемента используются Google в качестве заполнителей и динамически заполняются по мере открытия выпадающих списков.
Выберите выпадающие списки вопросов по следующей логике:
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
Нажмите на элемент, чтобы развернуть его:
child.click()
Затем сосредоточьтесь на содержании элементов вопроса:
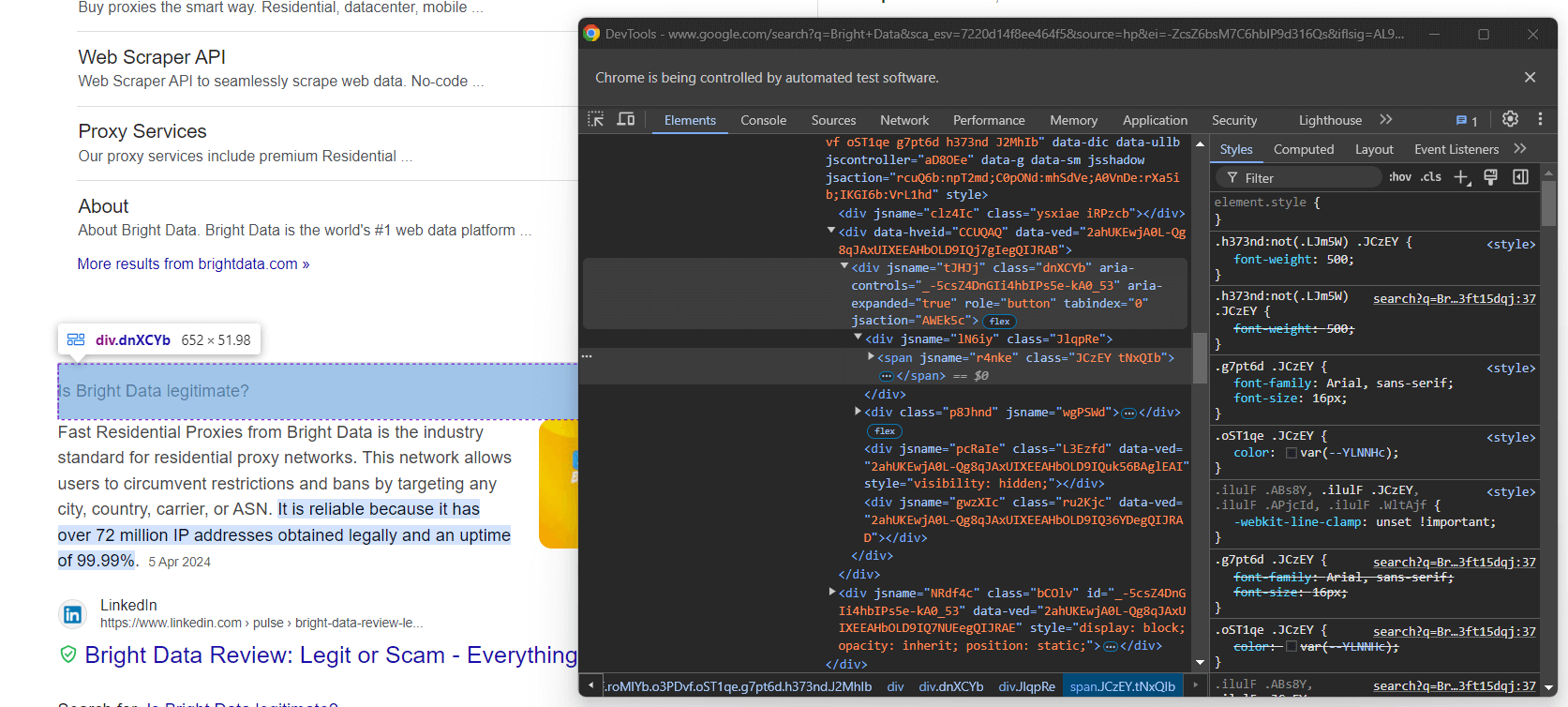
Обратите внимание, что вопрос содержится в <span> в узле aria-expanded="true". Выполните его парсинг следующим образом:
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
Затем просмотрите код элемента ответа:

Обратите внимание, как вы можете получить его, собрав текст в узле <span> с помощью атрибута lang в элементе data-attrid="wa:/description":
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
Затем просмотрите код необязательного изображения в поле ответа:

Вы можете получить его URL-адрес, перейдя к атрибуту src из элмента <img> с атрибутом data-ilt:
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
Поскольку элемент изображения необязателен, вы должны обернуть приведенный выше код блоком try... except. Если узел отсутствует в текущем вопросе, find_element () вызовет исключение NoSuchelementException. Код перехватит его и переместится дальше, в этом случае
Если вы пропустили шаг 4, импортируйте исключение:
from selenium.common import NoSuchElementException
Наконец, просмотрте код исходного раздела:

Вы можете получить URL-адрес источника, выбрав родительский элемент <a> элемента <h3>:
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
Используйте данные парсинга для заполнения нового объекта и добавления его в массив people_also_ask_questions:
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
Так держать! Вы только что выполнили парсинг раздела «Люди также спрашивают» со страницы Google.
Шаг 8. Экспортируйте данные парсинга в CSV.
Если вы напечатаете people_also_ask_questions, вы увидите следующий результат:
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has 150 million+ IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of 150 million+ IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
Конечно, это здорово, но было бы гораздо лучше, если бы это было в формате, которым можно было бы легко поделиться с другими членами команды. Итак, экспортируйте people_also_ask_questions в CSV-файл!
Импортируйте пакет csv из стандартной библиотеки Python:
import csv
Затем используйте его для заполнения выходного CSV-файла данными SERP:
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
Наконец-то! Ваш скрипт парсинга «Люди также спрашивают» создан.
Шаг 9. Объединение всего в одно целое
Ваш последний скрипт scraper.py должен содержать следующий код:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
В 100 строках кода вы только что создали парсер PAA!
Убедитесь, что оно работает, выполнив его. В Windows запустите парсер с помощью:
python scraper.py
В качестве альтернативы в Linux или macOS запустите:
python3 scraper.py
Дождитесь завершения работы парсера, и в корневом каталоге вашего проекта появится файл people_also_ask.csv. Откройте его, и вы увидите:

Поздравляем, миссия выполнена!
Заключение
Из этого урока вы узнали, что такое раздел «Люди также спрашивают» на страницах Google, какие данные в нем содержатся и как их парсить с помощью Python. Как вы узнали здесь, создание простого скрипта для автоматического извлечения данных из него занимает всего несколько строк кода Python.
Хотя представленное решение хорошо подходит для небольших проектов, оно нецелесообразно для крупномасштабного парсинга. Проблема в том, что у Google имеется одна из самых передовых технологий борьбы с ботами в отрасли. Поэтому он может заблокировать вас с помощью капчи или запретов на IP-адреса. Кроме того, масштабирование этого процесса на нескольких страницах увеличит затраты на инфраструктуру.
Означает ли это, что эффективный и надежный парсинг Google невозможен? Совсем нет! Вам просто нужно передовое решение, которое решит эти проблемы, например API Google Поиска от Bright Data.
API Google Поиска предоставляет конечную точку для получения данных со страниц поисковой выдачи Google, включая раздел «Люди также спрашивают». С помощью простого вызова API вы можете получить нужные данные в формате JSON или HTML. Узнайте, как начать работу с ним в официальной документации.
Зарегистрируйтесь сейчас и начните бесплатное опробование!





