
Раньше фильтрация данных была простым трюком в базе данных. Сегодня это основная бизнес-способность, которая обеспечивает работу искусственного интеллекта, соблюдение требований законодательства и помогает вам опередить конкурентов.
В этом руководстве вы узнаете:
- Что такое фильтрация данных.
- Почему фильтрация данных важна.
- Почему следует использовать автоматическую фильтрацию данных.
- Как Deep Lookup упрощает фильтрацию данных.
Давайте погрузимся!
Что такое фильтрация данных?
Фильтрация данных – это просто показ только тех данных, которые вас действительно интересуют. Думайте об этом, как об использовании фильтра для кофе, который дает вам только то, что вам нужно, а не то, что попало. Механика проста: вы устанавливаете правила (например, покажите мне клиентов из Калифорнии), а система исключает все, что не соответствует правилам.
Мы все используем фильтрацию данных в повседневной жизни. Когда вы ищете “беспроводные наушники до 100 долларов” на Amazon, вы используете фильтрацию. Когда ваша команда маркетологов составляет список клиентов, которые не совершали покупок в течение 6 месяцев, они фильтруют данные. Когда вы сортируете входящие сообщения по отправителям, вы фильтруете.
Хотя концепция проста, масштабное использование фильтрации данных в организации требует глубокого понимания данных и правильных инструментов. Сегодня фильтрация данных важна для успеха каждой организации, и мы расскажем вам, почему именно.
Почему фильтрация данных важна
Фильтрация необходима для осмысления больших данных.
Большинство компаний сегодня сидят на золотых жилах данных, которые они никогда не используют. Не потому, что данные не ценны, а потому, что они не могут эффективно копаться в них, чтобы найти то, что важно.
Подумайте об этом так. Ваша компания, вероятно, собирает сотни данных о каждом клиенте. Но когда наступит решающий момент и вам нужно будет определить наиболее ценные сегменты, неужели вы будете вручную разбирать 50 000 записей о клиентах? Конечно, нет. Вы возьмете выборку, сделаете несколько обоснованных предположений и будете надеяться на лучшее.
Именно эту проблему и решает фильтрация. Вот почему эффективная фильтрация данных крайне важна:
- Отсечение шума: ваши аналитики перестают тратить время на неактуальные данные и сосредотачиваются на закономерностях, которые действительно двигают иголку.
- Ускорение работы: меньшиемассивы данных означают более быстрые запросы, более быстрые выводы и решения, которые принимаются за несколько дней, а не недель.
- Обнаружение скрытых закономерностей: Когда вы убираете беспорядок, невидимые ранее тенденции внезапно становятся очевидными.
- Экономия реальных денег: Меньше данных для хранения и обработки означает снижение затрат на инфраструктуру. Кроме того, время вашей команды становится бесконечно более ценным.
- Соблюдайте требования законодательства: Автоматически отфильтровывайте конфиденциальную информацию, и вы будете спать спокойно, зная, что случайно не раскроете данные клиентов.
В общем, фильтрация данных – это мост между необработанными данными и принятием обоснованных решений. Далее мы рассмотрим, как подходить к фильтрации на практике, и некоторые стандартные приемы для эффективной фильтрации.
Ручная фильтрация данных на примере данных торговой площадки Amazon
Позвольте мне рассказать вам о том, как поступает большинство команд, когда им нужно отфильтровать данные. Мы будем использовать реальный набор данных о товарах Amazon (любезно предоставленный Bright Data datasets), чтобы показать вам, как именно это происходит. Этот набор данных включает в себя различные поля, такие как названия товаров, бренды, цены, рейтинги и многое другое из разных категорий и регионов.
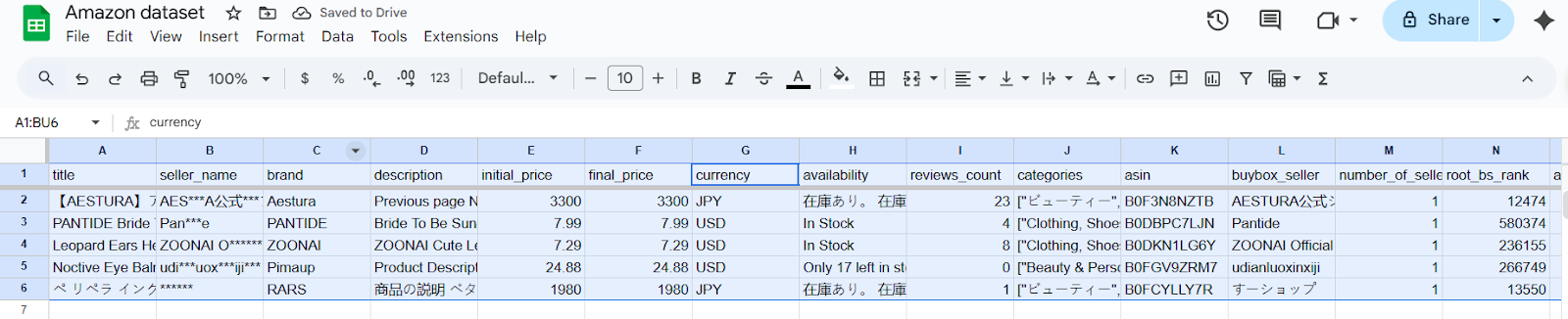
Столкнувшись с таким обширным списком, специалист по работе с данными должен выделить только те продукты, которые важны для конкретного анализа, чтобы сосредоточиться на полезной информации. Для этого необходимо выполнить следующие действия:
- Начните с фильтрации всех товаров, которые не соответствуют вашим первоначальным критериям интереса. На практике это часто означает исключение товаров, не относящихся к целевой категории или области применения. Например, если нас интересуют только косметические товары, мы удалим записи, относящиеся к другим категориям.
- Используя такой инструмент, как Google sheets или Excel, перейдите на вкладку “Данные” и нажмите на кнопку “Создать фильтр”.

- После этого в каждом столбце появится фильтр, с помощью которого вы сможете настроить набор данных так, как вам нужно.
- Например, если вы хотите отфильтровать продукты по валюте и оставить только те, которые имеют цену в долларах США, перейдите в столбец “Цена” и примените этот фильтр.

- Как только вы снимите отметку с JPY, в наборе данных будут отображаться только товары с ценой в долларах США.
Когда вы делаете это в первый раз, вы чувствуете себя очень хорошо. Вы контролируете ситуацию, видите, что именно происходит, и по ходу дела улавливаете интересные закономерности. “О, смотрите, экологичные продукты, похоже, имеют более высокие рейтинги!”
Но вот что происходит на практике:
- Неделя 1: Это здорово! Мне нравится, что у меня есть такой контроль.
- Неделя 4: Все повторяется, но я все еще нахожу хорошие идеи.
- Неделя 12: Я потратил все утро на применение тех же фильтров, которые использовал вчера.
- Неделя 24: Кажется, я забыл очистить предыдущий фильтр… эти цифры вообще правильные?
Многие блестящие аналитики сгорают, занимаясь именно этим. Не потому, что работа не имеет ценности, а потому, что они тратят 80 % своего времени на механические задачи, а не на реальный анализ.
Теперь, когда вы знаете, как фильтровать данные вручную, давайте рассмотрим плюсы и минусы использования этого метода.
Плюсы ручной фильтрации
- Ручная фильтрация дает вам немедленную визуальную обратную связь, позволяя мгновенно видеть результаты и итеративно корректировать фильтры. Вы можете обнаружить неожиданные закономерности или проблемы с качеством данных в процессе работы.
- Вы также получаете интеграцию бизнес-контекста, что позволяет принимать взвешенные решения. При фильтрации полей ‘customers_say’ или ‘top_review’ человеческая оценка выявляет настроения и проблемы, которые автоматические системы могут пропустить.
- Это обеспечивает гибкое исследование, которое поддерживает анализ на основе открытий. Вы можете заметить, что продукты с ‘climate_pledge_friendly’ = TRUE имеют более высокие рейтинги, что приведет к новым стратегическим открытиям.
- Низкий барьер для входа означает, что любой член команды, знакомый с электронными таблицами, может выполнять анализ без технического обучения или специализированных инструментов.
- Вы получаете возможность отслеживания аудита с помощью просмотра фильтров, а документированные критерии обеспечивают воспроизводимость анализа и совместную работу команды.
Минусы ручной фильтрации
- Ограничения масштаба быстро становятся очевидными. Фильтрация более 10 000 строк в Google Sheets приводит к заметному снижению производительности. При наличии миллионов товаров Amazon вы увидите лишь крошечную выборку.
- Временные затраты увеличиваются с ростом сложности. Применение 8-этапного процесса фильтрации, описанного выше, занимает 15-20 минут для одного анализа. Повторять это ежедневно или по нескольким категориям становится непосильной задачей.
- Вероятность человеческих ошибок возрастает с увеличением количества повторений. Случайный выбор неправильных операторов (больше, чем, или меньше, чем) или забывание очистить предыдущие фильтры приводит к неправильному анализу.
- Несогласованность между пользователями приводит к противоречивым выводам. Два аналитика могут по-разному интерпретировать “качественного продавца”, фильтруя ‘имя_продавца’ или ‘рейтинг’ с разными пороговыми значениями.
- Ограниченная воспроизводимость делает автоматизацию невозможной. Каждый сеанс ручной фильтрации требует вмешательства человека, что не позволяет создавать отчеты по расписанию или информационные панели в режиме реального времени.
- Стоимость возможностей значительна. Пока аналитики тратят часы на фильтрацию данных, конкуренты, использующие автоматизированные решения, уже действуют на основе полученных данных. Время, потраченное на механическую фильтрацию, можно было бы вложить в стратегический анализ и принятие решений.
В целом ручная фильтрация данных обеспечивает высокую степень контроля и ясности для аналитика, что делает ее хорошо подходящей для исследовательского анализа или небольших наборов данных, где важно понимание нюансов. Однако его неэффективность и риск ошибок при работе с крупными данными делают его менее подходящим для больших данных или рутинных рабочих процессов.
В таких случаях лучше перейти на автоматизированные методы или инструменты фильтрации, и сейчас мы расскажем вам, почему.
Почему автоматическая фильтрация данных умнее, быстрее и масштабируемее
Когда мы говорим об автоматизированной фильтрации, речь идет не только о скорости. Автоматизация не просто делает то, что вы делали раньше, быстрее, она делает то, что вы буквально не могли сделать вручную.
Помните тот набор данных Amazon с 73 различными полями? Вручную вы могли бы исследовать 5-10 комбинаций этих полей. С помощью автоматизации вы можете параллельно тестировать тысячи комбинаций. Вы можете обнаружить, что товары со значками “За защиту климата” на самом деле на 23 % лучше удерживают покупателей, но только в определенных ценовых диапазонах и только при продаже определенными типами продавцов.
Это не те открытия, на которые вы наткнулись. Такие открытия появляются при систематическом изучении всех аспектов, и найти их можно только с помощью автоматической фильтрации данных.
Автоматизированная фильтрация в корне меняет возможности аналитика или компании, обрабатывая миллионы записей за считанные секунды и применяя сотни комбинаций фильтров одновременно. Это достигается за счет кодирования ваших критериев в виде правил, исполняемых машиной, и их непрерывного выполнения в масштабе.
Вместо того чтобы перебирать столбцы, вы можете определить декларативные фильтры, применить их как можно ближе к источнику и получить быстрые, пригодные для повторного использования данные. Благодаря автоматизированной фильтрации данных вы можете параллельно исчерпывающе изучать тысячи полевых взаимодействий, выявляя закономерности, которые никогда не уложились бы в ограниченный бюджет исследования человеком, и затем воспроизводить их сколько угодно.
| Размеры | Вручную | Автоматизированный |
|---|---|---|
| Скорость/задержка | В человеческом темпе; от нескольких минут до нескольких часов на выполнение | Машинный темп; от нескольких секунд до нескольких минут при масштабировании |
| Масштабируемость | Ограничена пользовательским интерфейсом и памятью | Горизонтальное масштабирование (распределенные вычисления, pushdown) |
| Надежность | Восприимчивость к человеческим ошибкам | Детерминированность, тестируемость, идемпотентность |
| Свежесть | Пакетная, специальная | По расписанию или в потоковом режиме; возможно использование в режиме, близком к реальному времени |
| Согласованность | Зависит от оператора | Логика с контролем версий; воспроизводимые результаты |
| Стоимость | Скрытые трудозатраты; переделки | Оптимизация вычислений; кэширование и вытеснение предикатов |
| Управление | Трудно поддается аудиту | История, протоколирование, утверждения, контроль доступа |
Одним из лучших инструментов для автоматической фильтрации данных является Deep Lookup от Brightdata, о котором мы поговорим далее.
Представляем Deep Lookup: Фильтрация данных с помощью простого английского языка
Deep Lookup – это инструмент исследования Bright Data на основе искусственного интеллекта, который превращает подсказки на простом английском языке в структурированные и точные наборы данных. С помощью Deep Lookup вы можете запросить именно то, что вам нужно, и получить это в виде таблицы, которую можно использовать.
Вместо того чтобы сшивать источники вместе или писать сложные запросы, вы описываете нужные вам сущности (компании, продукты, людей, новости, свойства), фильтры, которым они должны соответствовать, и столбцы, которые вы хотите видеть. Deep Lookup выполняет фильтрацию, обогащение и структурирование за кулисами, предоставляя готовые к анализу результаты.
Как работает Deep Lookup
Deep Lookup поощряет двухстрочный формат запроса, например, такой:
- Найти все … <существа и условия>.
- Показать: <нужные столбцы>.
Например, пример Deep Lookup будет выглядеть следующим образом:
***Найдите все товары Amazon для красоты и личной гигиены по цене ≤ $25 с рейтингом ≥ 4 и в наличии.***
***Показать: название продукта, бренд, текущая цена, рейтинг, количество отзывов, URL-адрес продукта***.
Deep Lookup берет это описание и:
- Определяет источники данных, которые ему нужны
- Применяет ваши фильтры на уровне базы данных (а не после загрузки всего)
- Обогащает результаты дополнительным контекстом
- Возвращает чистый, структурированный набор данных, который можно сразу же использовать.
Для более сложных запросов можно использовать более структурированный подход:
FIND ALL: [типы сущностей]
ФИЛЬТРЫ:
- Условие #1
- Условие #2
ШОУ:
- Колонка №1 [Обогащение или ограничение]
- Столбец #2 [Обогащение или ограничение]
Ключевое отличие заключается в том, что вы описываете бизнес-логику, а не техническую реализацию. Вам не нужно знать, к каким конечным точкам API обращаться, как обрабатывать пагинацию или где найти данные о ценах конкурентов.
Наборы данных, которые вы получаете от Deep Lookup, курируются, структурируются и предоставляются в виде наборов Websets. Наборы Websets проверены и полностью цитируемы, настраиваемы (выбирайте точные поля) и разработаны так, чтобы оставаться актуальными по мере того, как Deep Lookup сканирует новые источники.
На практике все происходит следующим образом:
- Задайте свой вопрос
- Проанализируйте и оцените.
- Получение практических результатов.
Вы можете настраивать Websets по организациям, секторам, географии и полям данных в соответствии с вашими потребностями.
Подведение итогов
Теперь вы поняли, что фильтрация данных – это способ превратить беспорядочную, перегруженную информацию в четкие решения. Ручная фильтрация развивает интуицию, но автоматизация обеспечивает скорость, последовательность и возможность выявить закономерности, которые никто не может найти по одному столбцу.
Именно здесь на помощь приходит Bright Data. С помощью Deep Lookup вы излагаете свои критерии на простом английском языке и получаете чистый, структурированный, всегда свежий набор данных, который можно подключать к информационным панелям, блокнотам или моделям. В сочетании с наборами данных Bright Data (например, набором данных Amazon в этом руководстве) вы перейдете от идеи к пониманию и производству, не поддерживая хрупкие конвейеры.
Готовы увидеть, что автоматическая фильтрация может сделать с вашими данными? Попробуйте Deep Lookup с бесплатной учетной записью Bright Data. Возьмите правила фильтрации, которые вы применяли вручную, и посмотрите, какие сведения вы упустили.






