

В этом руководстве вы узнаете:
- Что такое Pipedream и зачем его использовать.
- Причина, по которой вы должны интегрировать его со встроенным плагином для скраппинга.
- Преимущества интеграции Pipedream с архитектурой скраппинга Bright Data.
- Пошаговое руководство по созданию рабочего процесса веб-скреппинга с помощью Pipedream.
Давайте погрузимся в него!
Pipedream с первого взгляда: Автоматизируйте и интегрируйте с легкостью
Pipedream – это платформа для создания и запуска рабочих процессов, соединяющих различные приложения и сторонних поставщиков. Она предоставляет функциональные возможности как без кода, так и с низким кодом. Благодаря этим возможностям вы можете автоматизировать процессы и интегрировать системы с помощью предварительно созданных компонентов или пользовательского кода.
Ниже представлены его основные характеристики:
- Визуальный конструктор рабочих процессов: Определяйте рабочие процессы с помощью визуального интерфейса, подключая предварительно созданные компоненты для популярных приложений. В настоящее время он обеспечивает интеграцию для 2700+ приложений.
- Не требует кода: Не требует технических знаний. Однако для сложных задач в приложения Pipedream могут быть встроены узлы пользовательского кода. Поддерживаются такие языки программирования, как Node.js, Python, Go и Bash.
- Архитектура, управляемая событиями: Рабочие процессы запускаются такими событиями, как HTTP/webhooks, запланированное время, входящие электронные письма и т. д. Таким образом, рабочий процесс остается бездействующим и не потребляет никаких ресурсов до тех пор, пока не произойдет определенное событие.
- Бессерверное выполнение: Основная функциональность Pipedream связана с бессерверной средой выполнения. Это означает, что вам не нужно предоставлять серверы или управлять ими. Pipedream выполняет рабочие процессы в масштабируемой среде по требованию.
- ИИ, создающий рабочие процессы: Deal with String– ИИ, предназначенный для написания пользовательских агентов, которые требуют от вас только вставки подсказок. Его можно использовать и в том случае, если вы не особо знакомы с Pipedream. Вы можете написать подсказку и позволить ИИ построить рабочий процесс за вас.
Почему бы просто не написать код? Преимущества готовой интеграции скрапинга
Pipedream поддерживает действия с кодом. Они позволяют писать полноценные скрипты с нуля на выбранном вами языке (среди поддерживаемых). Технически это означает, что вы можете создать бота-скрепера полностью в Pipedream, используя эти узлы.
С другой стороны, это не обязательно упрощает процесс построения рабочего процесса скрапинга. Вы все равно столкнетесь с обычными проблемами и препятствиями, связанными с защитой от скрапинга.
Поэтому практичнее, эффективнее и быстрее полагаться на встроенный плагин для скраппинга, который справится с этими сложностями за вас. Именно такой опыт предоставляет интеграция Bright Data в Pipedream.
Ниже приведен список наиболее важных причин, по которым стоит положиться на готовый к использованию плагин для скраппинга Bright Data:
- Простая аутентификация: Pipedream надежно хранит ваш ключ Bright Data API (необходимый для аутентификации) и обеспечивает удобство использования. Вам не нужно писать собственный код для аутентификации, и вы точно не раскроете свой ключ.
- Преодоление систем защиты от ботов: API-интерфейсы Bright Data справляются со всеми проблемами веб-скрапинга, от ротации прокси и управления IP-адресами до решения CAPTCHA и парсинга данных. Таким образом, это гарантирует, что ваш рабочий процесс Pipedream получит последовательные и высококачественные веб-данные.
- Структурированные данные: После соскабливания вы получаете структурированные, упорядоченные данные, не написав ни строчки кода. Плагин позаботится о структурировании данных за вас.
Ключевые преимущества сочетания Pipedream с плагином Bright Data Plugin
Подключив возможности автоматизации Pipedream к Bright Data, вы сможете:
- Получите доступ к свежим данным: Цель веб-скреппинга – получить данные из Интернета, и Bright Data поможет вам в этом. Тем не менее, данные со временем меняются. Поэтому, если вы не хотите, чтобы ваши аналитические выкладки устарели, вам необходимо постоянно извлекать свежие данные. Вот тут-то и пригодится мощь Pipedream (например, с помощью триггеров планирования).
- Интегрируйте искусственный интеллект в рабочие процессы скрапбукинга: Pipedream интегрируется с несколькими LLM, такими как ChatGPT и Gemini. Это позволяет автоматизировать несколько задач, для выполнения которых потребовались бы часы ручной работы. Например, вы можете построить рабочий процесс RAG для мониторинга списка товаров конкурентов на сайте электронной коммерции.
- Упростите технические моменты: На веб-сайтах используются сложные методы блокировки, которые обновляются почти каждую неделю. Интеграция Bright Data позволяет обойти эти блокировки, поскольку она берет на себя все решения по борьбе с ботами.
Пришло время увидеть интеграцию Bright Data в действии в рабочем процессе Pipedream!
Постройте рабочий процесс скрапинга на основе искусственного интеллекта с помощью Pipedream и Bright Data: Пошаговое руководство
В этом разделе вы узнаете, как построить рабочий процесс Pipedream, который использует Bright Data для получения данных о продукте Amazon. В частности, целевой страницей будет:
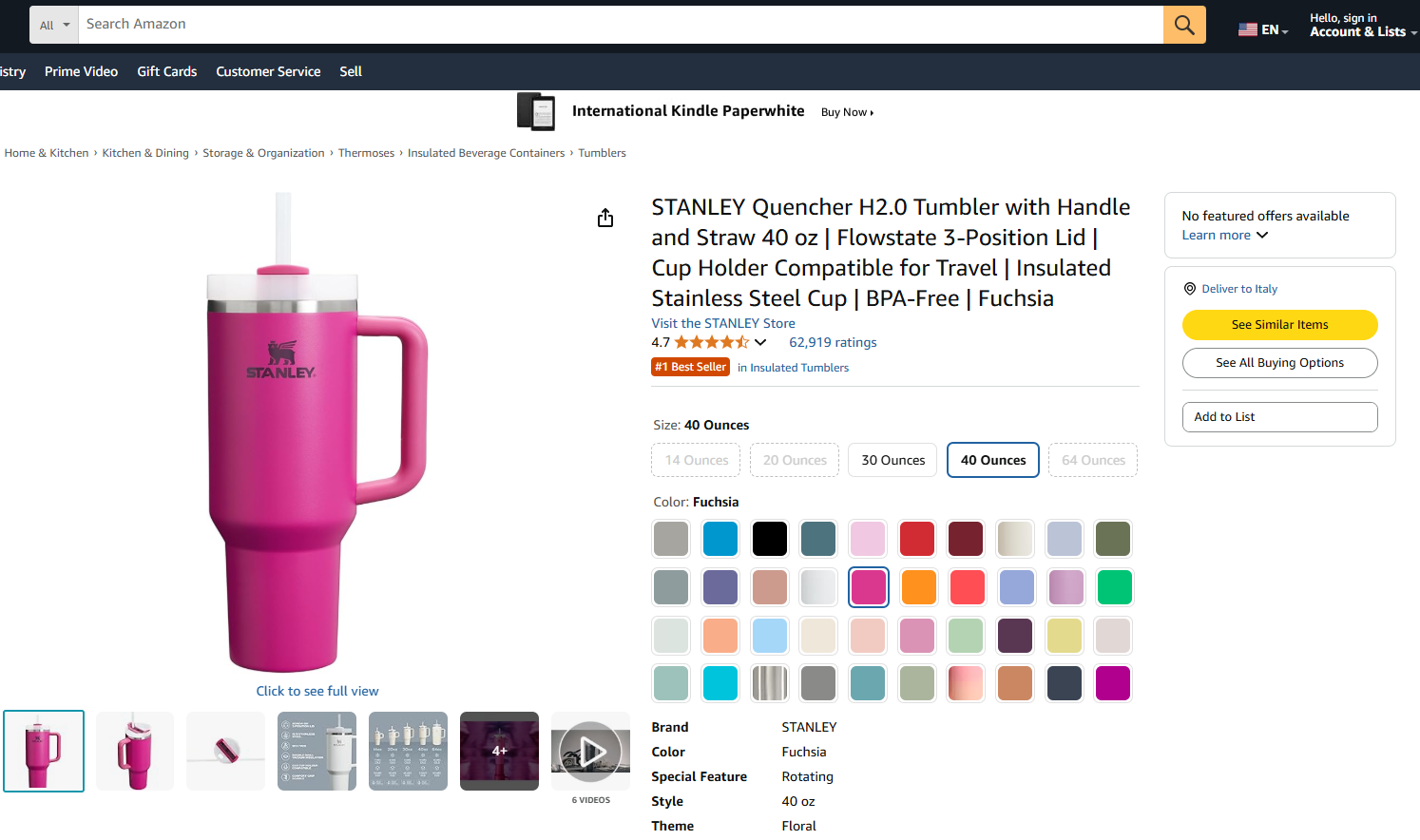
Цель состоит в том, чтобы показать вам, как создать рабочий процесс Pipedream, который выполняет следующие действия:
- Получает данные с целевой веб-страницы с помощью интеграции Bright Data.
- Вносит данные в LLM.
- Попросите LLM проанализировать данные и составить на их основе резюме продукта.
Следуйте приведенным ниже инструкциям, чтобы узнать, как создать, протестировать и развернуть такой рабочий процесс в Pipedream.
Требования
Чтобы воспроизвести этот учебник, вам понадобятся:
- Аккаунт Pipedream (достаточно бесплатного аккаунта).
- Ключ API Bright Data.
- Ключ API OpenAI.
Если у вас их еще нет, воспользуйтесь приведенными выше ссылками и следуйте инструкциям, чтобы все настроить.
Эти знания также помогут вам следовать учебнику:
- Знакомство с инфраструктурой и продуктами Bright Data (особенно с Web Scraper API).
- Базовое понимание обработки ИИ (например, LLM).
- Знание того, как работают триггеры и вызовы API через веб-крючки.
Шаг № 1: Создайте новый рабочий процесс Pipedream
Войдите в свою учетную запись Pipedream и перейдите на панель управления. Затем создайте новый рабочий процесс, нажав кнопку “Новый рабочий процесс”:
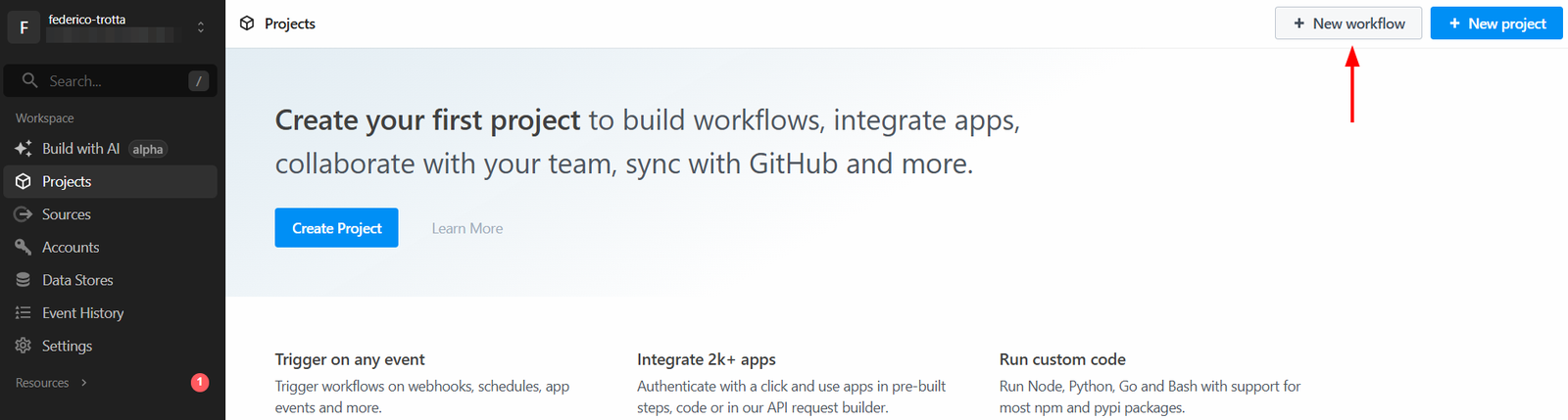
Система предложит вам создать новый проект. Дайте ему название и нажмите кнопку “Создать проект”, когда закончите:
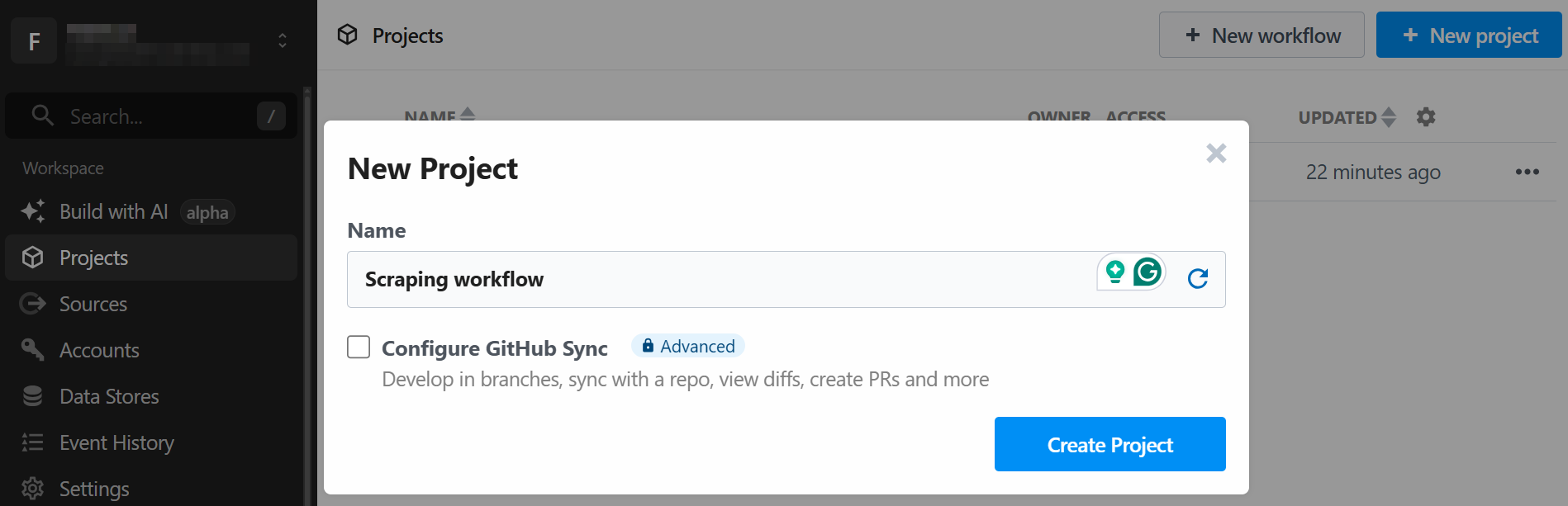
Инструмент попросит вас присвоить имя рабочему процессу и определить его настройки. Вы можете оставить все настройки как есть и в конце нажать кнопку “Создать рабочий процесс”:
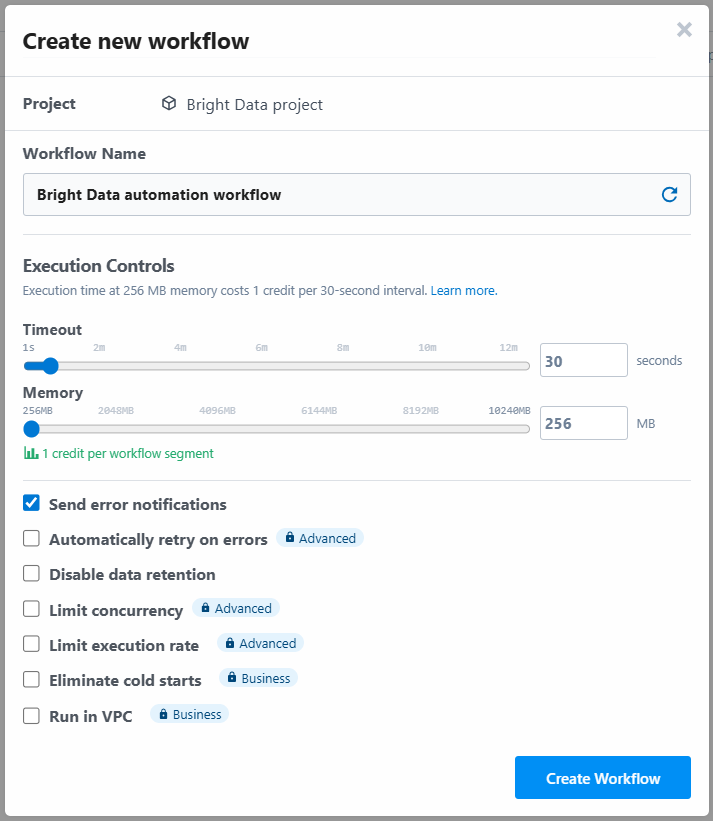
Ниже показан пользовательский интерфейс вашего нового рабочего процесса:
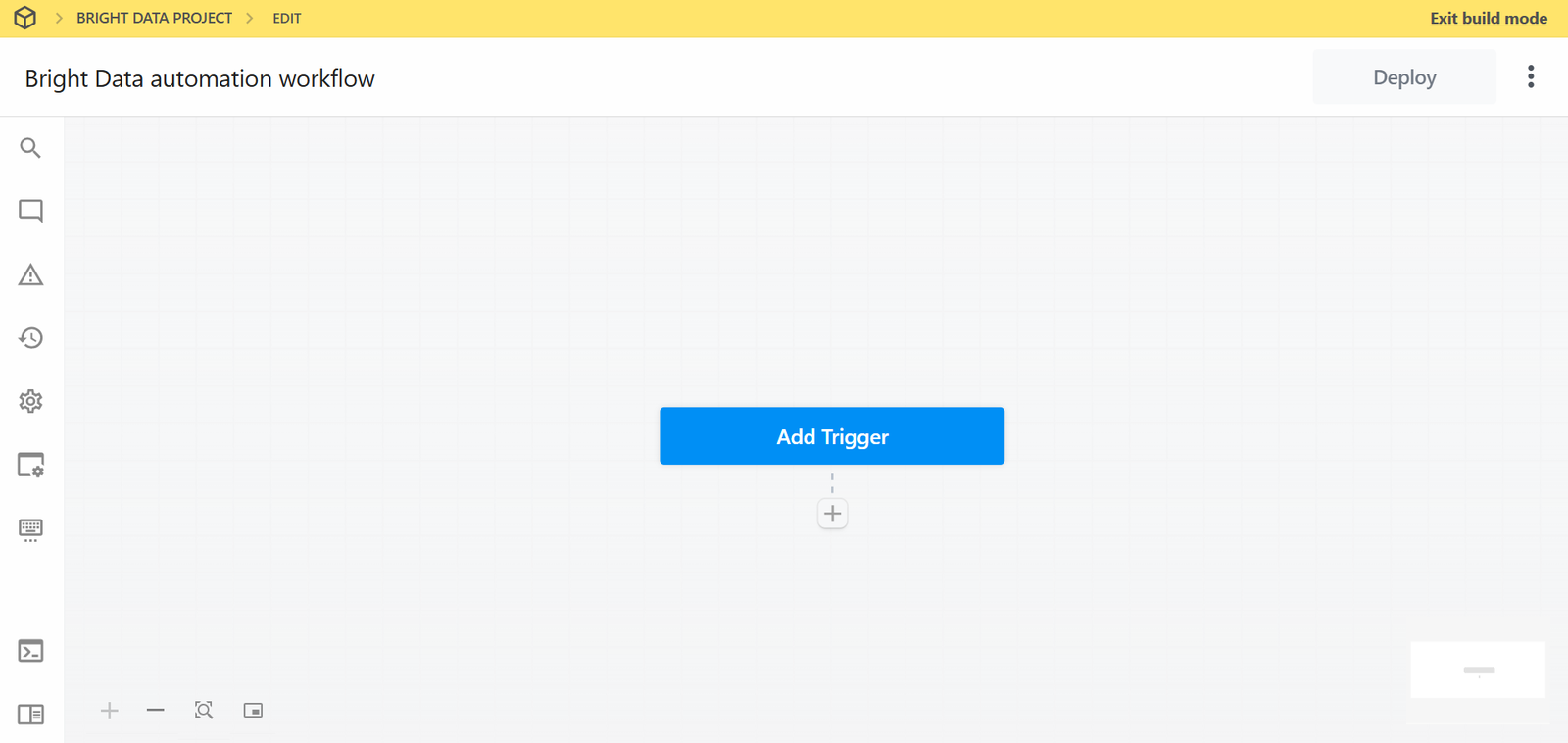
Очень хорошо! Вы создали новый рабочий процесс в Pipedream. Теперь вы готовы добавить к нему интеграцию плагинов.
Шаг № 2: Добавьте триггер
В Pipedream каждый рабочий процесс начинается с триггера. Нажав на кнопку “Добавить триггер”, вы увидите триггеры, которые вы можете выбрать:
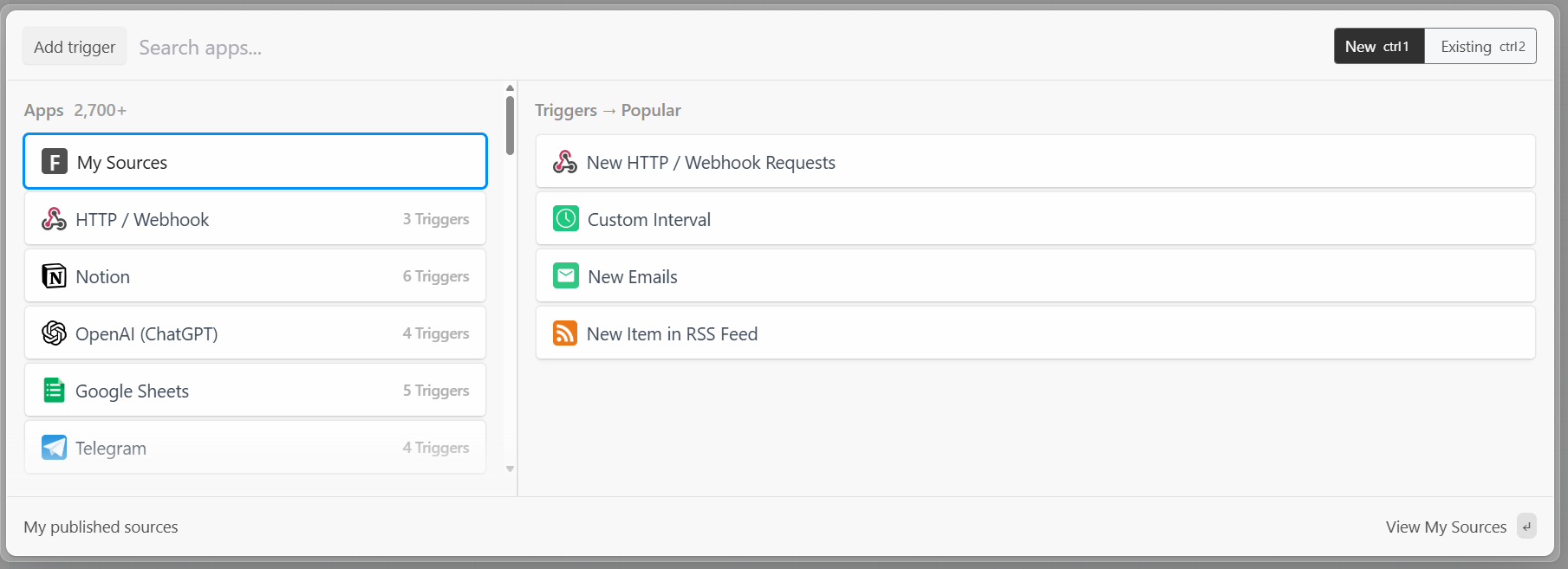
В этом случае выберите триггер “Новые HTTP/Webhook-запросы”, который необходим для подключения к Bright Data. Оставьте данные заполнителя как есть и нажмите кнопку “Сохранить и продолжить”:
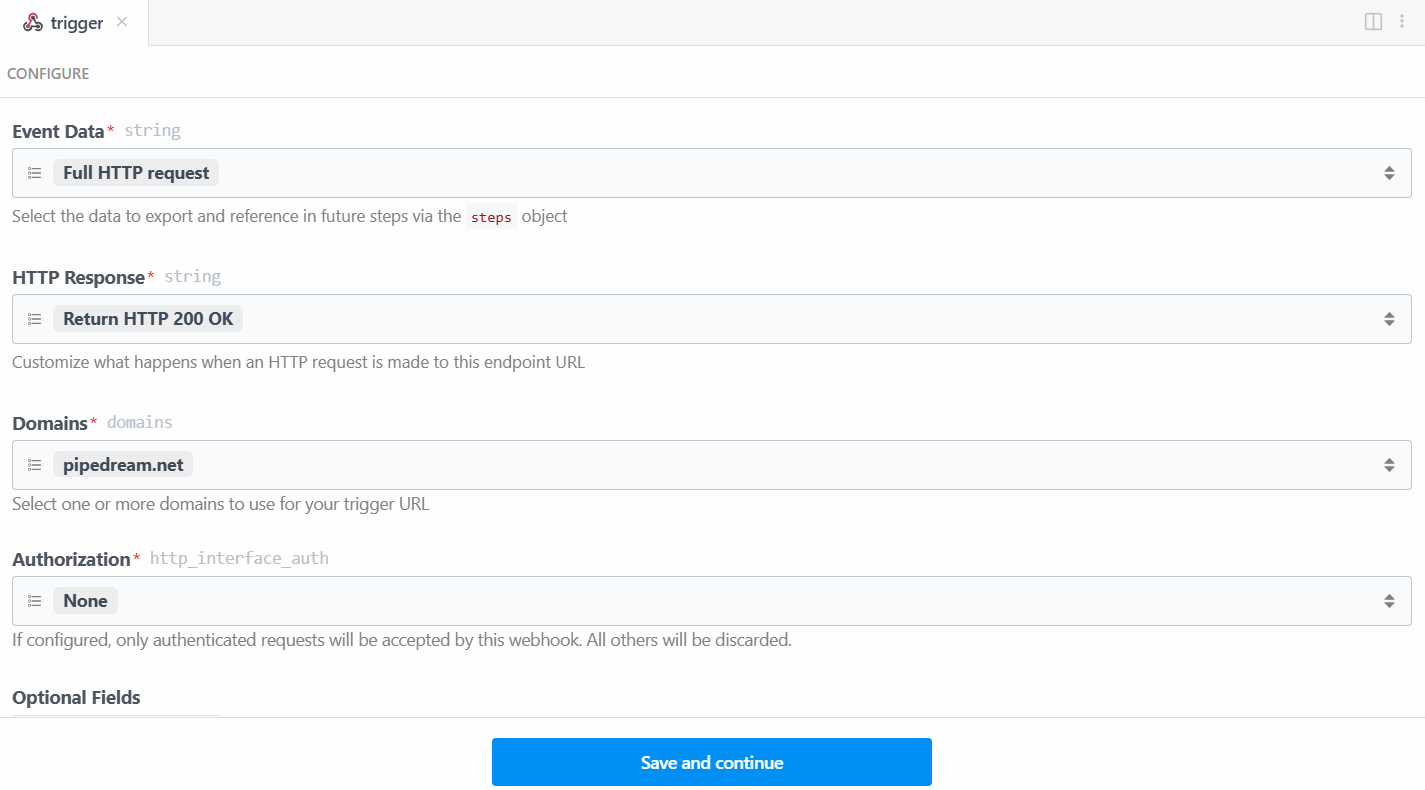
Чтобы триггер заработал, необходимо сгенерировать событие. Поэтому нажмите на кнопку “Сгенерировать тестовое событие”:
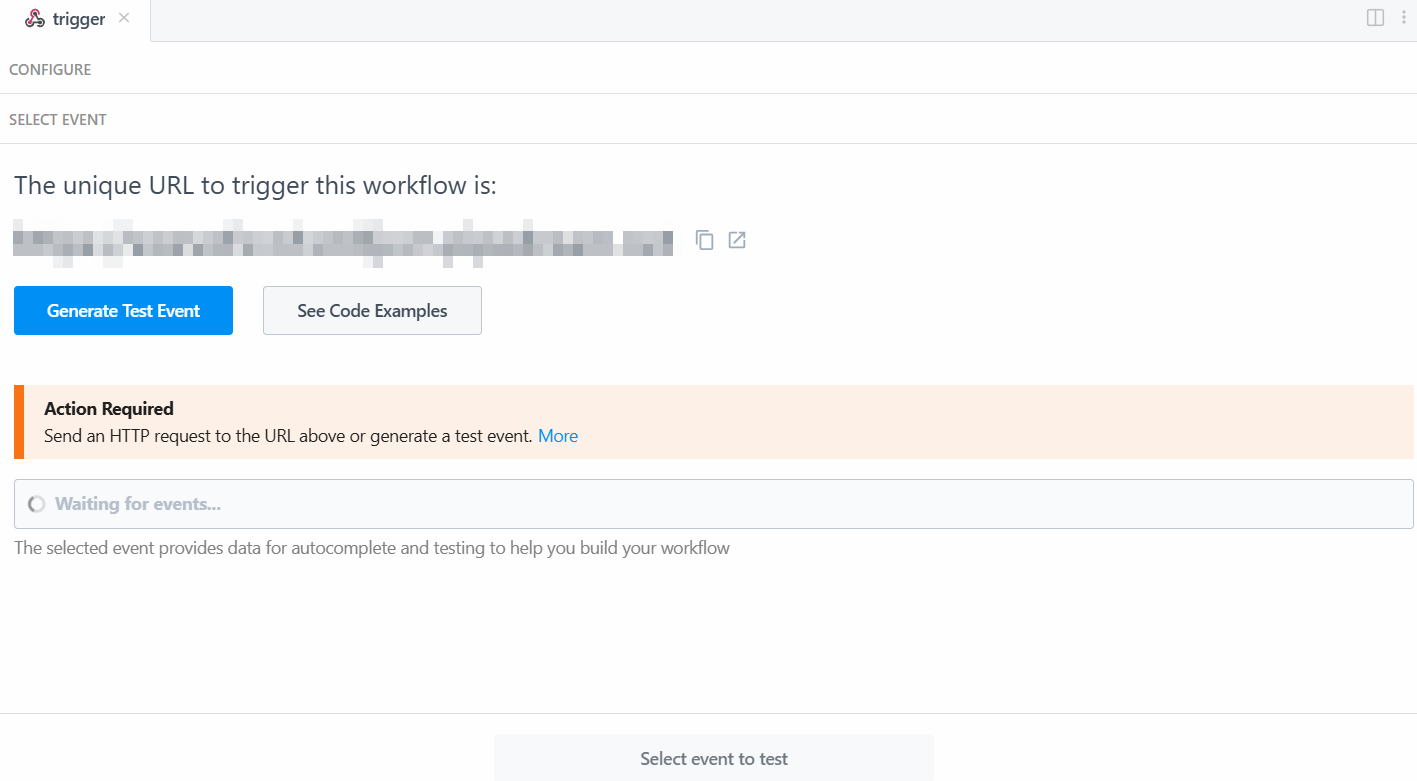
Система предоставляет вам заранее определенное значение тестового события следующим образом:
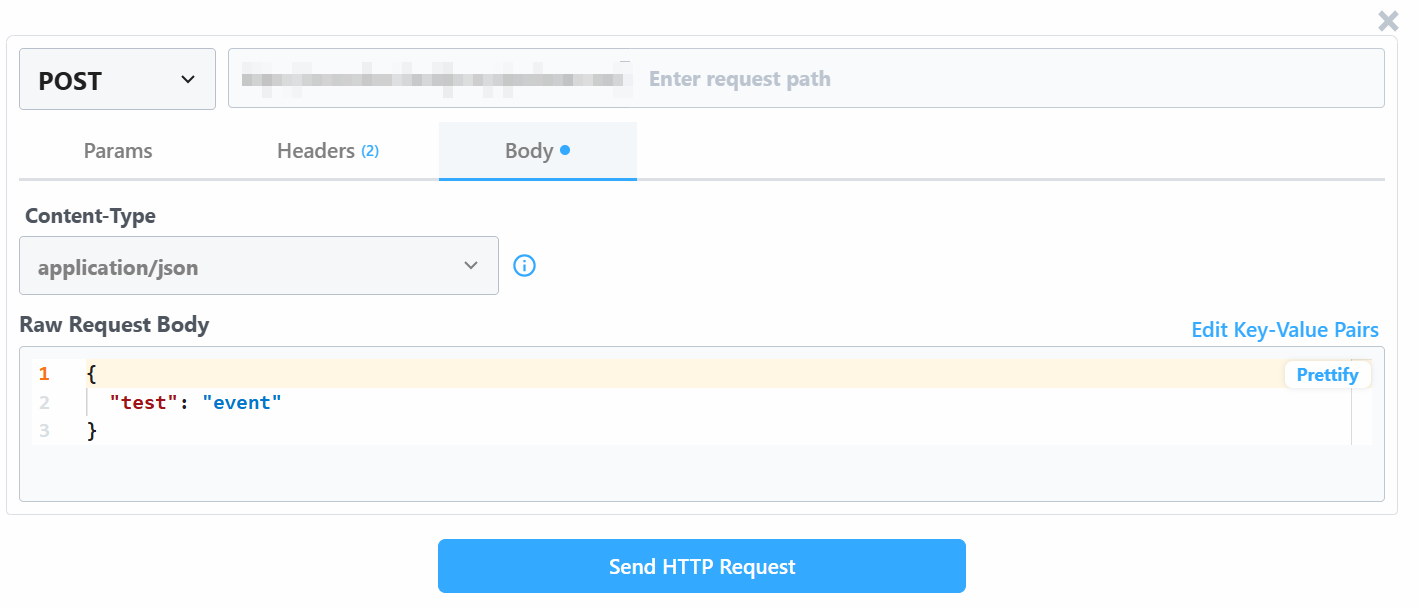
Измените значение “Raw Request Body” на:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
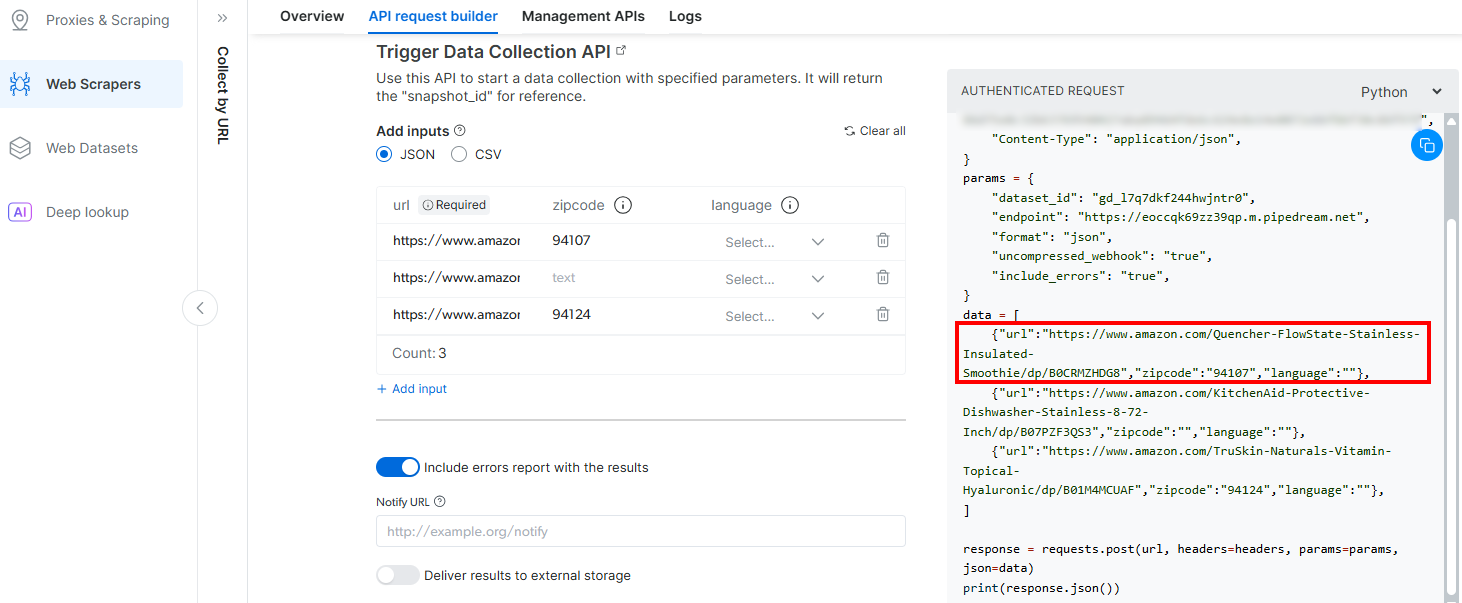
}Причина в том, что триггер, сгенерированный Pipedream, инициирует обращение к API Amazon Scraper компании Bright Data. Конечная точка (которая будет настроена позже) требует входных данных в этом конкретном формате полезной нагрузки. Вы можете убедиться в этом, проверив раздел “Конструктор API-запросов” в скрепере “Сбор по URL” в Aamzon Web Scraper’s Bright Data:
Вернитесь в окно Pipedream и, когда все будет готово, нажмите кнопку “Отправить HTTP-запрос”. Если все прошло как ожидалось, вы увидите сообщение об успехе в разделе результатов. Триггер также окрасится в зеленый цвет:
Отлично! Триггер для запуска интеграции Bright Data в рабочем процессе соскабливания Pipedream настроен правильно. Теперь вы готовы добавить действие.
Шаг № 3: Добавьте шаг действия “Яркие данные
После триггера вы можете добавить шаг действия в рабочий процесс Pipedream. Сейчас вам нужно подключить шаг Bright Data к триггеру. Для этого нажмите на “+” под триггером и найдите “bright data”:
Pipedream предоставляет вам несколько действий из плагина Bright Data. Выберите его, чтобы увидеть их все:
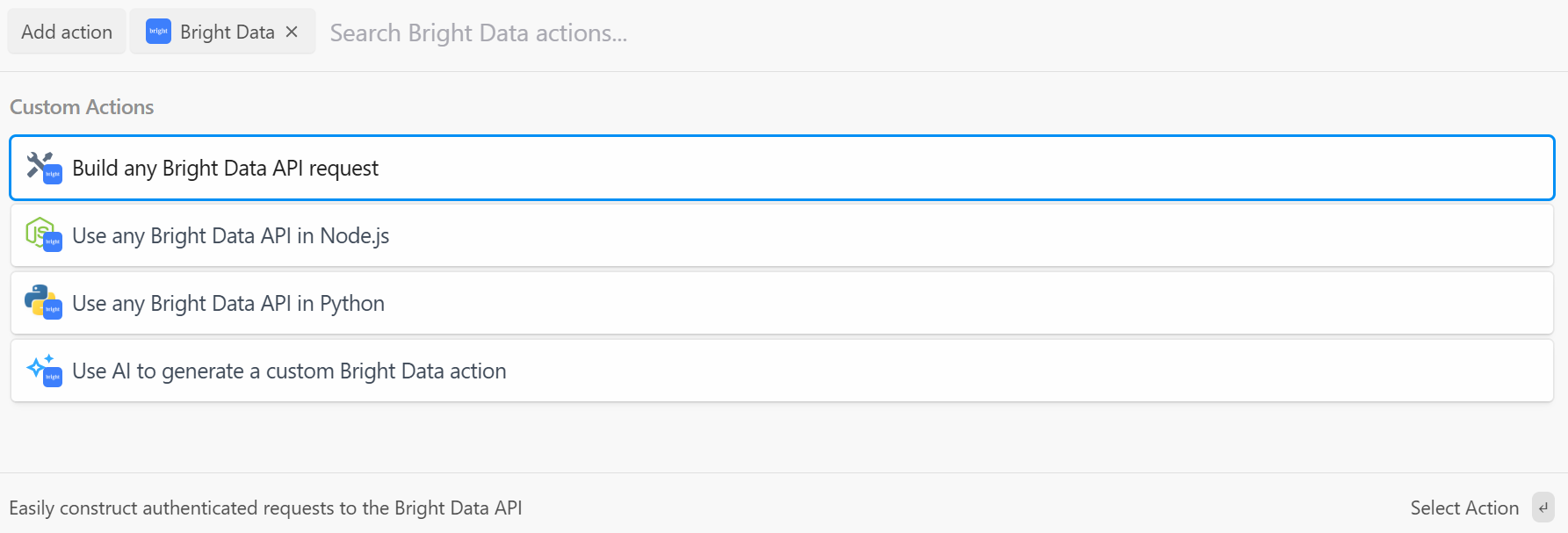
У вас есть следующие варианты:
- Создавайте любые запросы к API Bright Data: Создавайте аутентифицированные запросы к API Bright Data.
- Используйте любой API Bright Data в Node.js/Python: Подключите свой аккаунт Bright Data к Pipedream и настройте запросы в Node.js/Python.
- Используйте ИИ для создания пользовательского действия Bright Data: Попросите ИИ сгенерировать пользовательский код для Bright Data.
Для этого урока выберите опцию “Использовать любой API Bright Data в Python”. Вот что вы увидите:
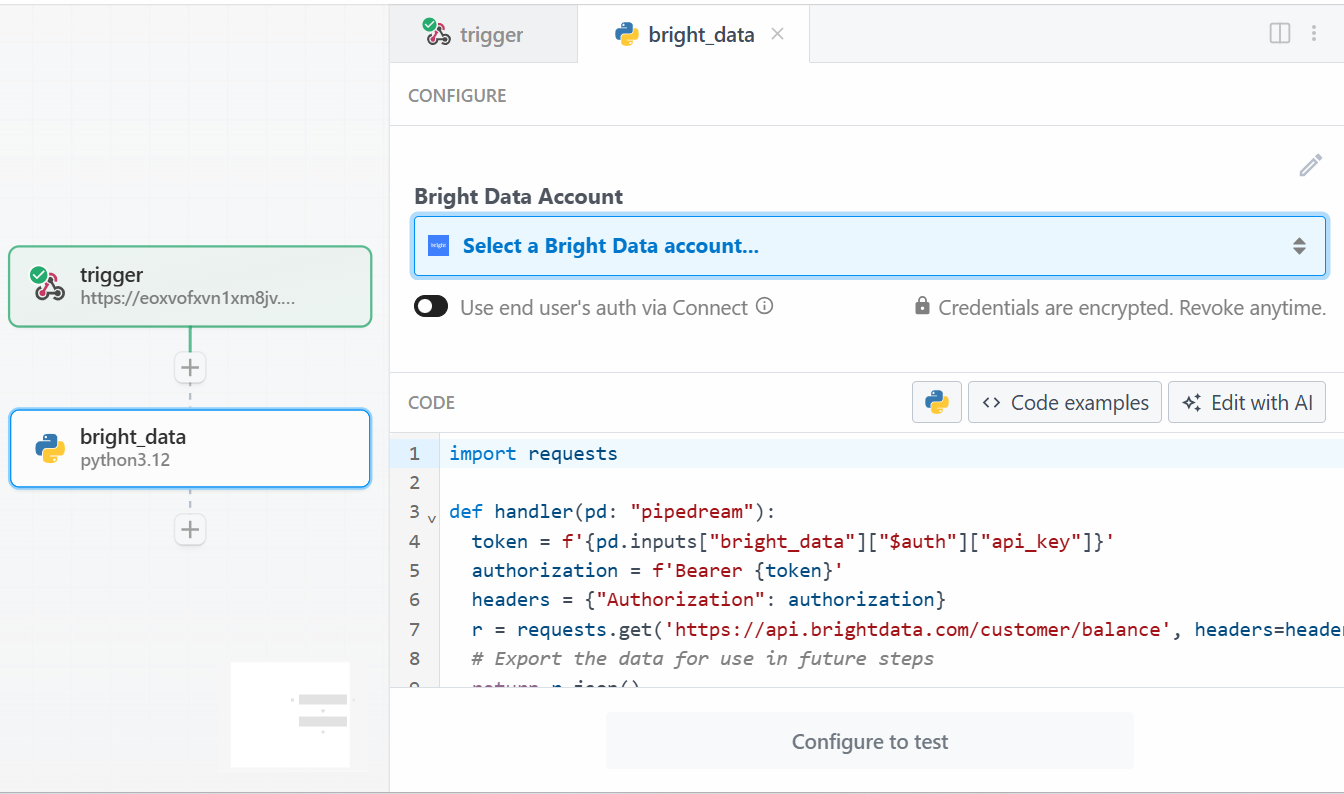
Сначала нажмите “Выбрать учетную запись Bright Data” в разделе “Учетная запись Bright Data” и добавьте свой ключ API Bright Data. Если вы еще не сделали этого, обязательно следуйте официальному руководству по настройке ключа API Bright Data.
Затем удалите код в разделе “CODE” и напишите следующий:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}Этот код выполняет следующие действия:
- Функция
handler()управляет рабочим процессом на уровне Pipedream. Она:- Извлекает ключ API Bright Data после того, как вы сохранили его в Pipedream.
- Конфигурирует запрос Bright Data API, указывая целевой URL, идентификатор набора данных и все необходимые для него данные.
- Управляет ответом. Если что-то пойдет не так, вы увидите ошибки в журналах Pipedream.
- Функция
poll_and_retrieve_snapshot()опрашивает Bright Data API на предмет получения моментального снимка, пока он не будет готов. Когда он готов, она возвращает запрошенные данные. Если что-то идет не так, она обрабатывает ошибки и показывает их в журналах.
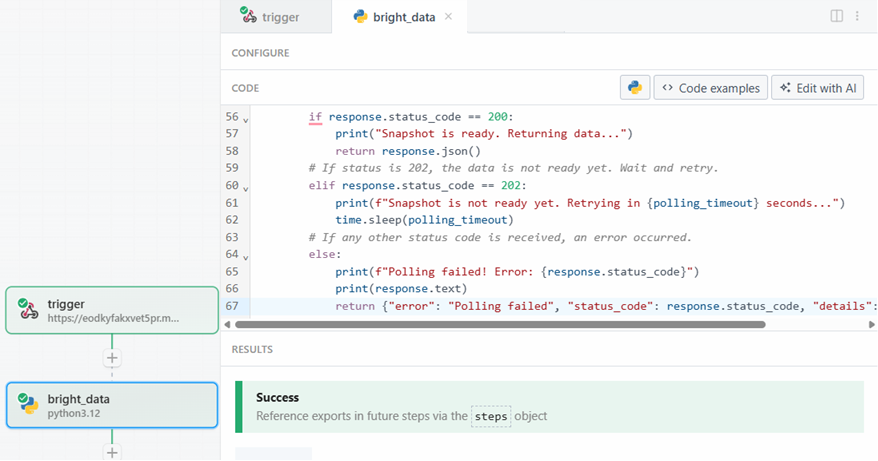
Когда вы будете готовы, нажмите на кнопку “Тест”. Вы увидите сообщение об успехе в разделе “Результаты”, а шаг действия “Яркие данные” будет окрашен в зеленый цвет:
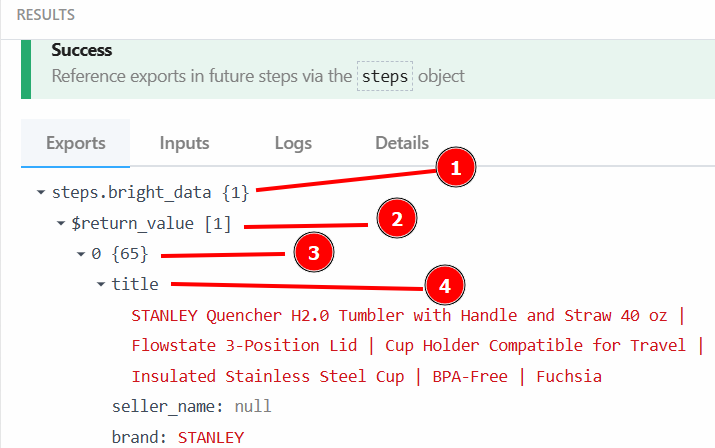
В разделе “Экспорт” под заголовком “Результаты” вы можете увидеть собранные данные:
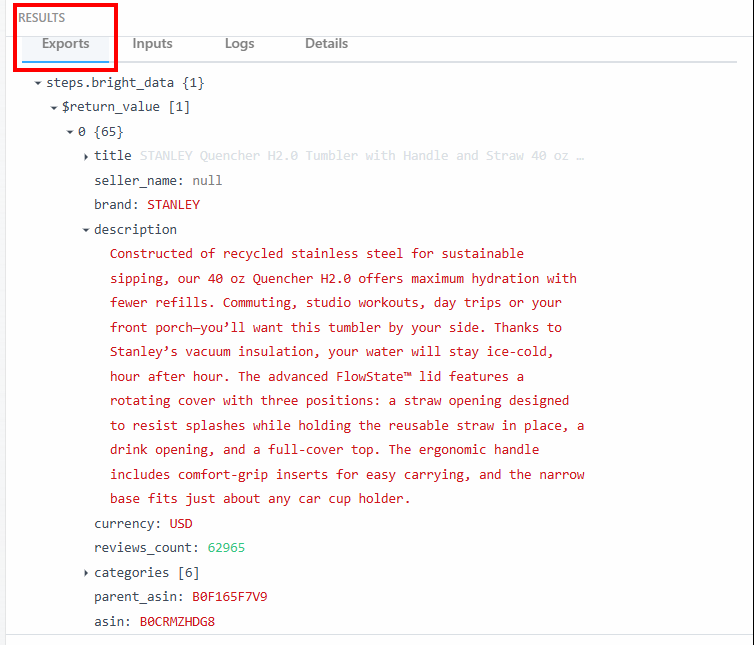
Ниже приведены данные в виде текста:
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}Вы будете использовать эти данные и их структуру на следующем этапе рабочего процесса.
Отлично! Вы правильно соскребли целевые данные благодаря действию Bright Data в Pipedream.
Шаг #4: Добавьте шаг действия OpenAI
Данные о товарах Amazon были успешно соскоблены интеграцией Beight Data. Теперь вы можете передать их в LLM. Для этого добавьте новое действие, нажав на кнопку “+”, и найдите “openai”. Здесь вы можете выбрать один из вариантов:

Выберите опцию “Построить любой запрос API OpenAI (ChatGPT)”, затем выберите опцию “Чат”:
Ниже приведен раздел конфигурации этого шага:
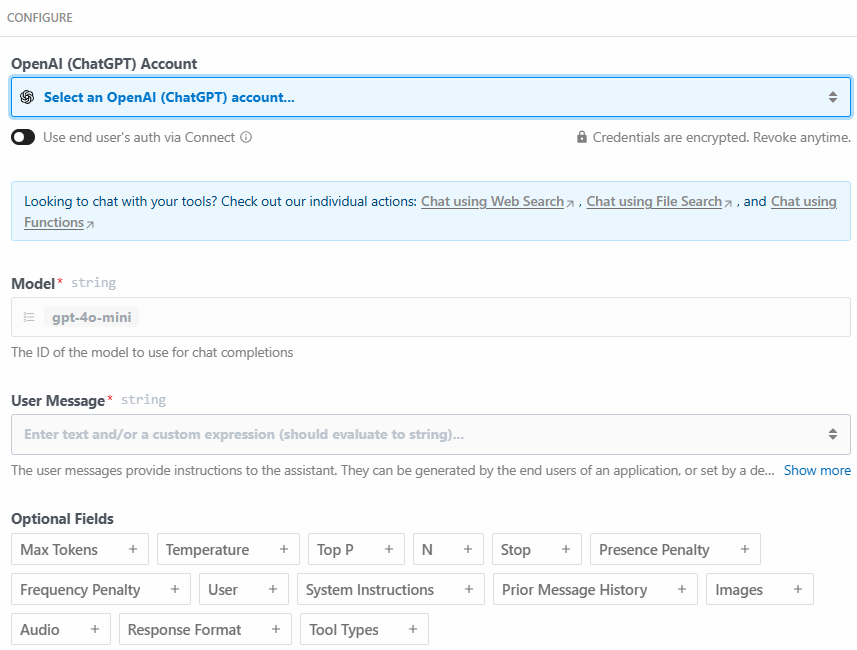
Нажмите на кнопку “Выберите аккаунт OpenAI (ChatGPT)…”, чтобы добавить свой API-ключ платформы OpenAI. Затем напишите следующее сообщение в разделе “Сообщение пользователя”:
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.В подсказке LLM предлагается:
- Действуйте как эксперт-аналитик продукта. Это важно, потому что, используя эту инструкцию, LLM будет вести себя так, как вел бы себя эксперт-аналитик. Это поможет сделать его ответ специфичным для данной отрасли.
- Рассмотрите данные, извлеченные на этапе “Яркие данные”, такие как название и описание продукта. Это поможет LLM сосредоточиться на конкретных данных, которые вам нужны.
- Представьте краткую информацию о продукте, основанную на изученных данных. В запросе также указано, что должно содержать резюме. Именно здесь вы увидите возможности ИИ-автоматизации для составления краткого описания продукта. LLM создаст резюме продукта на основе полученных данных, выступая в роли специалиста по продуктам.
Название продукта можно получить с помощью {{steps.bright_data.$return_value[0].title}}, поскольку, как указано в предыдущем шаге, структура выходных данных шага действия Bright Data такова:
После нажатия кнопки “Test” найдите вывод LLM в разделе “RESULTS” шага действий OpenAI Chat в разделе “Generated message” > “content”:
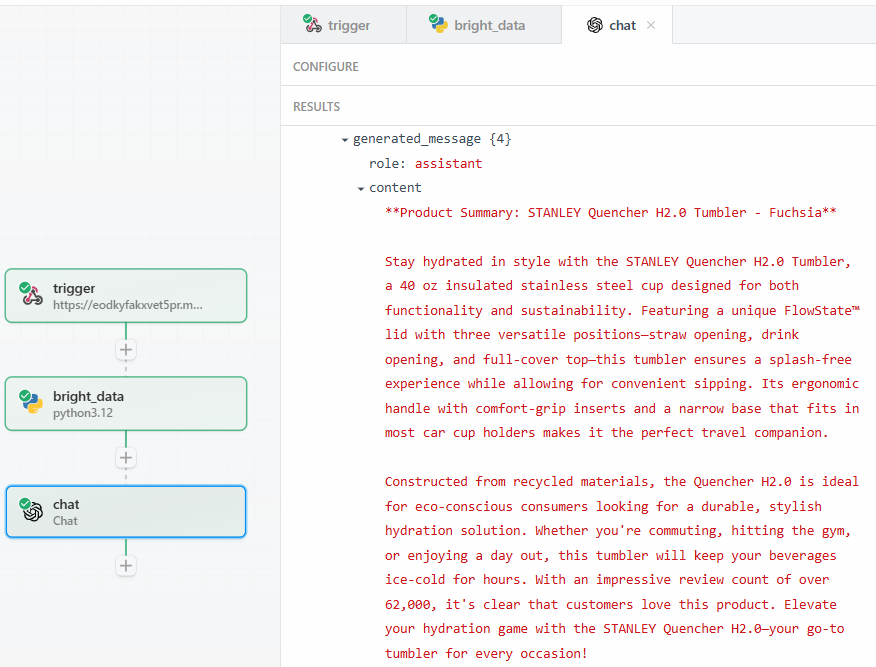
Ниже приведен возможный текстовый результат:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!Как видите, LLM предоставил краткое описание продукта, выступив в роли специалиста по продукту. Резюме в точности соответствует запросу:
- Что представляет собой продукт.
- Некоторые из его важных особенностей.
Причина, по которой вы хотите получить точные данные, такие как количество оценок, заключается в том, чтобы убедиться, что у LLM нет галлюцинаций. В резюме говорится, что количество отзывов превышает 62’000. Если вы хотите увидеть точное число, вы можете проверить его в поле “содержание” в результатах:
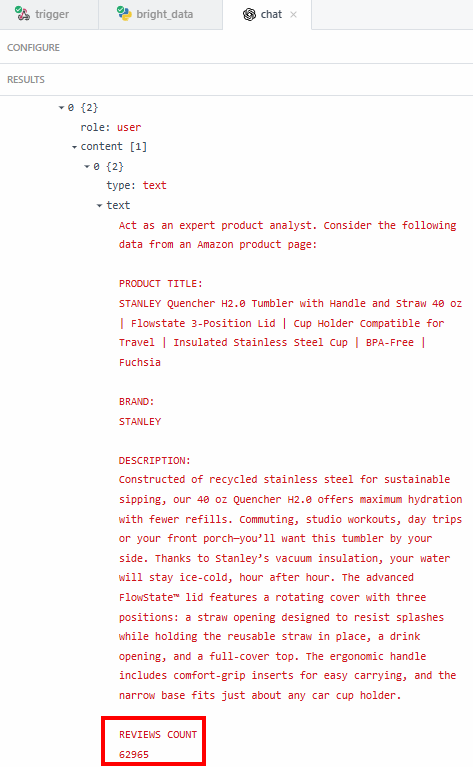
Затем проверьте, совпадает ли этот номер с тем, который указан на странице товара Amazon.
Наконец, если вы когда-нибудь пытались скреативить крупные сайты электронной коммерции, такие как Amazon, вы знаете, как трудно сделать это самостоятельно. Например, вы можете столкнуться с пресловутым Amazon CAPTCHA, который может заблокировать большинство скреперов:
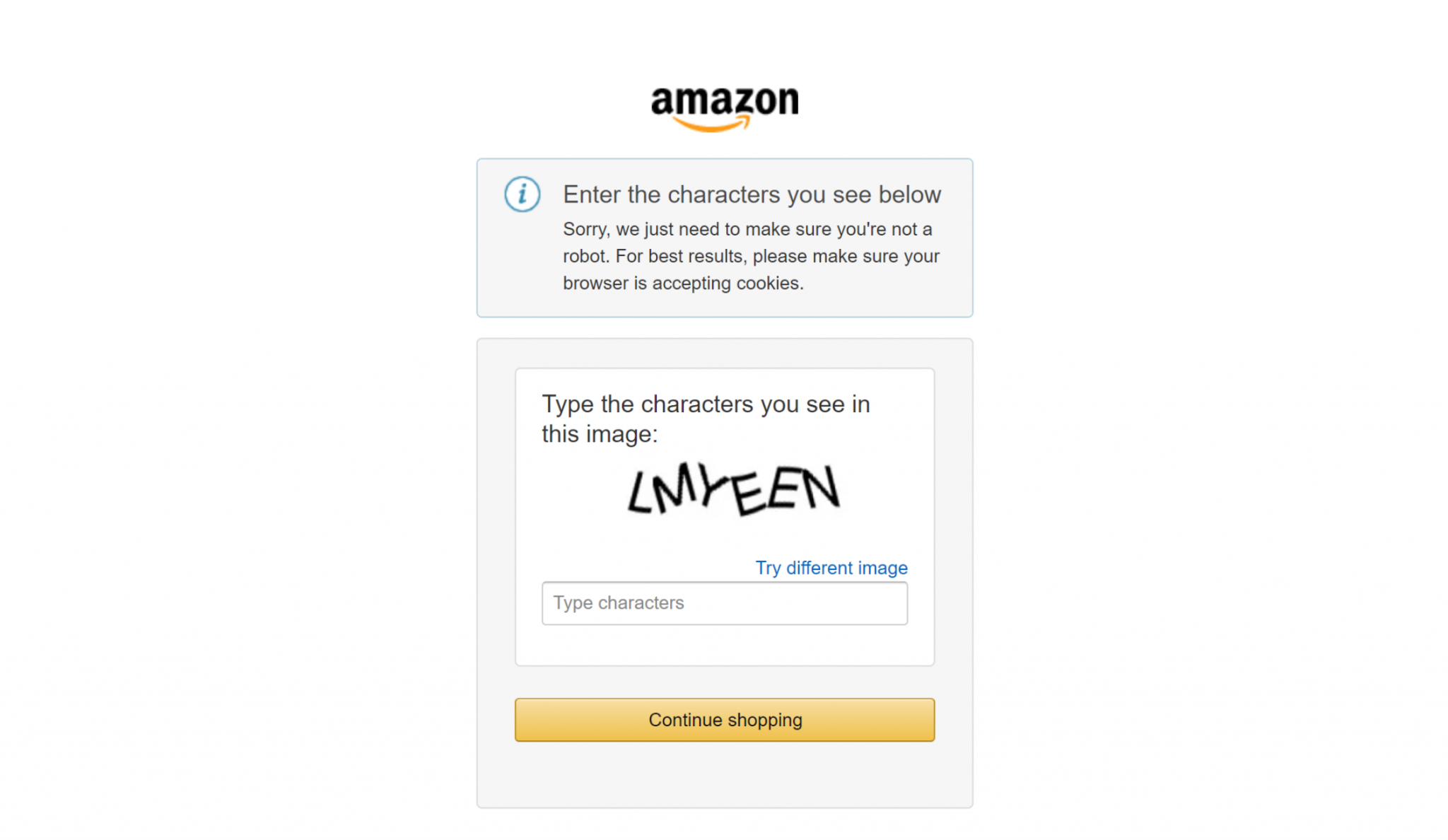
Именно здесь интеграция с Bright Data играет решающую роль в ваших рабочих процессах, связанных со скраппингом. Она обрабатывает все меры по борьбе со скрапингом за кулисами и обеспечивает бесперебойную работу процесса извлечения данных.
Потрясающе! Вы успешно протестировали шаг LLM. Теперь вы готовы развернуть рабочий процесс.
Шаг № 5: Развертывание рабочего процесса
Чтобы развернуть рабочий процесс, нажмите на одну из кнопок “Развернуть”:
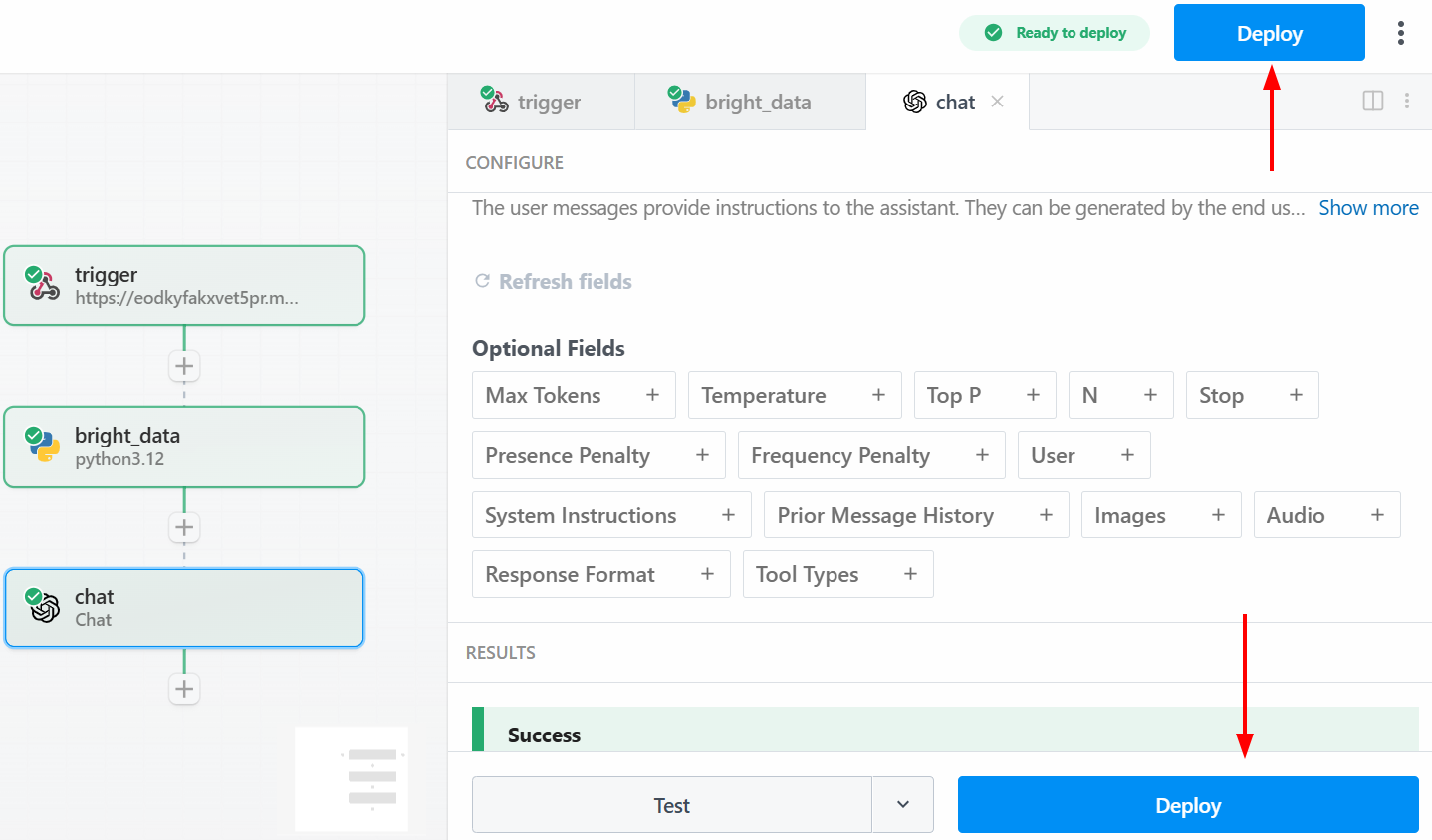
Ниже показано, что вы увидите после развертывания:
Чтобы запустить весь рабочий процесс, нажмите “Генерировать событие”:
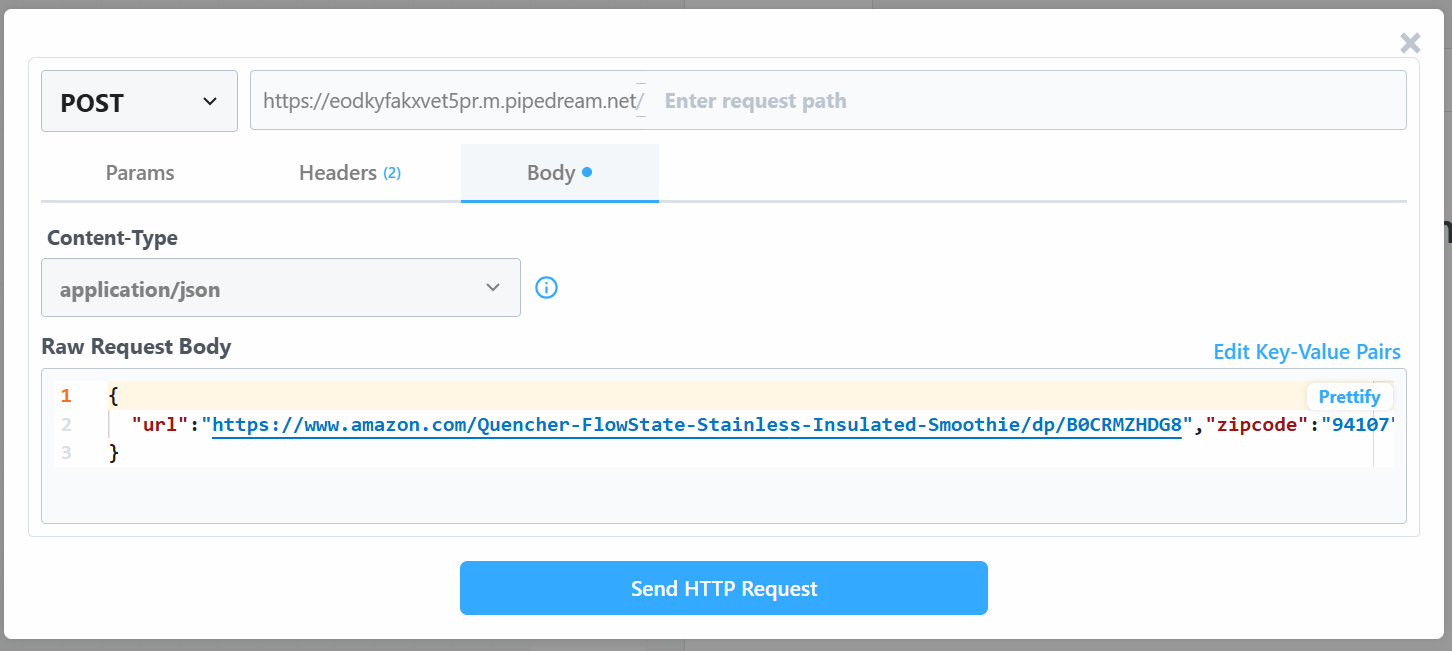
Нажмите на “Отправить HTTP-запрос”, чтобы запустить рабочий процесс, и он будет полностью запущен. Чтобы увидеть результаты развернутых рабочих процессов, перейдите в раздел “История событий” на главной странице. Выберите интересующий вас рабочий процесс и посмотрите результаты в разделе “Экспорт”:
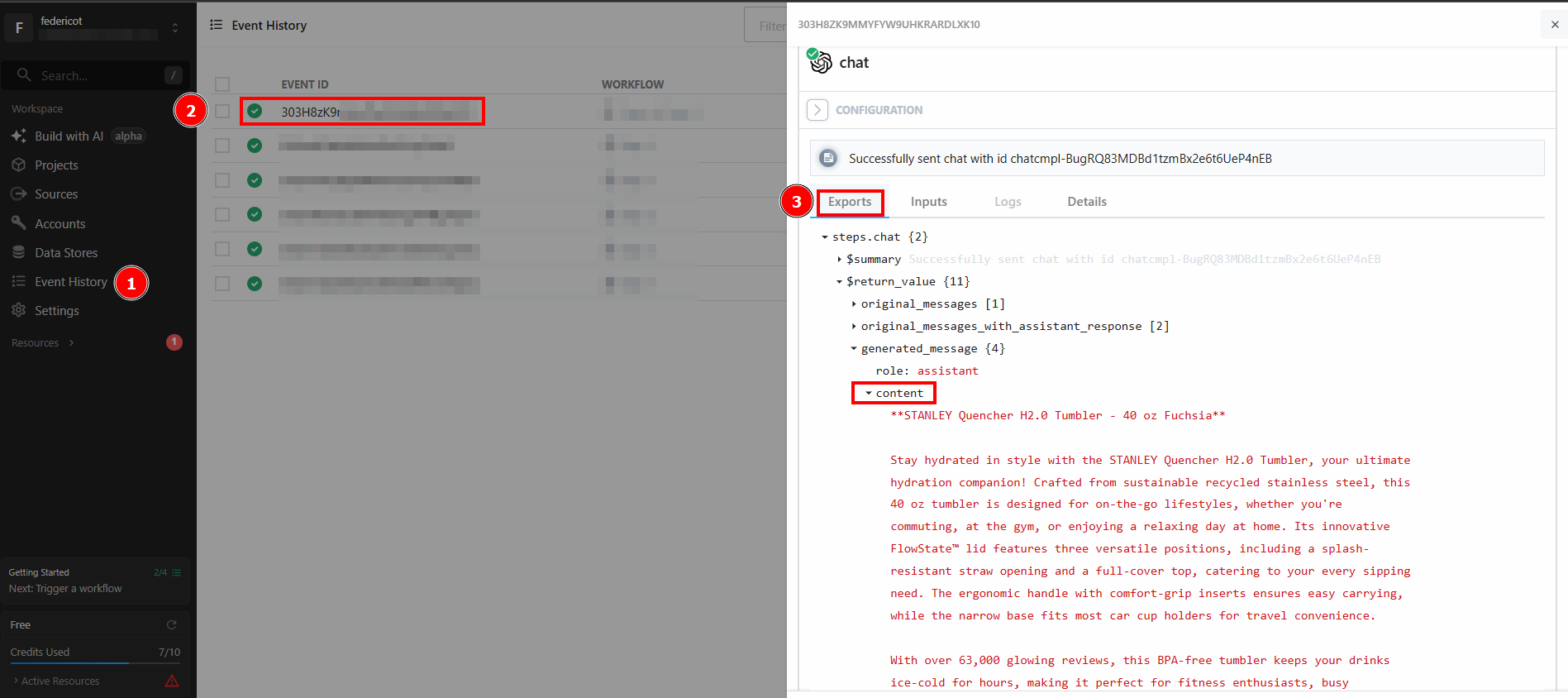
И вуаля! Вы создали и развернули свой первый рабочий процесс скраппинга в Pipedream с использованием Bright Data.
Заключение
В этом руководстве вы узнали, как построить автоматизированный рабочий процесс веб-скрепинга с помощью Pipedream. Вы на собственном опыте убедились, что интуитивно понятный интерфейс платформы в сочетании с интеграцией скрапинга Bright Data позволяет легко создавать сложные конвейеры скрапинга за считанные минуты.
Главная задача любой автоматизации, основанной на данных, – обеспечить постоянный поток чистых и надежных данных. Pipedream предоставляет механизм автоматизации и планирования, а инфраструктура искусственного интеллекта Bright Data справляется со сложностями веб-скреппинга и предоставляет готовые к использованию данные. Такая синергия позволяет вам сосредоточиться на создании ценности данных, а не на технических трудностях, связанных с их получением.
Создайте бесплатную учетную запись Bright Data и начните экспериментировать с нашими инструментами для работы с данными с искусственным интеллектом уже сегодня!





