

Без вкраплений индустрия ИИ и технологии в целом были бы практически неузнаваемы. Магистранты не понимали бы вас, поисковые системы не знали бы, что вы ищете, а все остальные рекомендательные системы выплевывали бы случайный хлам.
Следуйте за нами, и мы узнаем, как работают вкрапления и какова их важность в машинном обучении.
Что такое эмбеддинги?
Машины не понимают слов, но они понимают числа. Когда вы пишете код на любом программном языке, путем компиляции или интерпретации, он в конечном итоге превращается в двоичный или шестнадцатеричный код (оба числовых формата), который машина может понять.
В искусственном интеллекте, особенно в машинном обучении, модель должна понимать информацию. Именно здесь на помощь приходят вкрапления. С помощью вкраплений мы можем преобразовывать слова, изображения и любые другие виды информации в машиночитаемые числа. Это позволяет ИИ находить закономерности, взаимосвязи и смысл.
Машины понимают цифры, а не слова. Вкрапления – это мост между человеческими данными и искусственным интеллектом.
Почему вкрапления имеют значение
Представьте себе мир, в котором вы ищете пиццерию и получаете рекомендации по тако. При веб-скреппинге представьте, что вы спрашиваете у ChatGPT или Claude советы по Python и получаете инструкции по уходу за домашним питоном!
Вкрапления позволяют моделям понимать ваши намерения. Без них большинство систем будут работать, сопоставляя ваш точный текст с чем-то в своей базе данных.
- LLMS: Благодаря вкраплениям эти модели могут понять, что вы на самом деле говорите. Без них LLM не сможет понять смысл ваших слов… Помните советы по Python?
- Рекомендации: Такие компании, как Netflix, используют их наряду с фильтрацией и некоторыми другими методами, чтобы рекомендовать сериалы, которые вам действительно понравятся.
Встраивания позволяют машинам не просто считывать данные, но и понимать их.
Векторы: Язык вкраплений
В своей простейшей форме вектор – это просто список. Представьте, что вы хотите представить список ноутбуков. Каждый ноутбук имеет такие данные, как ОС, производитель процессора, вычислительные ядра и оперативная память.
Если у нас есть два ноутбука, их можно представить следующим образом.
- Ноутбук для Windows:
["Windows", "Intel", 4, "8"]. - Chromebook:
["ChromeOS", "Mediatek", 8, "4"].
Матрицы: Объединение векторов в таблицы
Матрица – это список списков. Технические пуристы поправят меня и назовут ее вектором векторов… но, как мы выяснили ранее, вектор – это просто список. Когда человек смотрит на матрицу, мы воспринимаем ее как таблицу.
Вот наша человекочитаемая матрица.
| OS | Производитель процессора | Ядра процессора | ОПЕРАТИВНАЯ ПАМЯТЬ (ГБ) |
|---|---|---|---|
| Windows | Intel | 4 | 8 |
| ChromeOS | Mediatek | 8 | 4 |
Наша матрица – это вектор векторов (список списков). Как видите, это сложнее для чтения, но все равно понятно. Для машины это действительно легче, чем таблица выше, но мы все еще не оптимизированы для машинного чтения.
[
["Windows", "Intel", 4, 8],
["ChromeOS", "Mediatek", 8, 4]
]Для того чтобы он был действительно машиночитаемым, нам нужно заменить слова цифрами. Мы присвоим номер каждому из наших нечисловых признаков.
OS
- Windows: 0
- ChromeOS: 1
Производитель процессора:
- Intel: 0
- Mediatek: 1
На этом этапе наша “таблица” полностью теряет человеческую читабельность. Однако машины прекрасно справляются с числами. Это позволяет машинам эффективно обрабатывать эти данные для поиска взаимосвязей.
[
[0, 0, 4, 8],
[1, 1, 8, 4]
]Это идеальный вариант для машины. Машины не читают слова, но они могут обнаружить закономерности в числах. В таком формате модель может эффективно анализировать наши данные и искать закономерности.
Как работают вкрапления
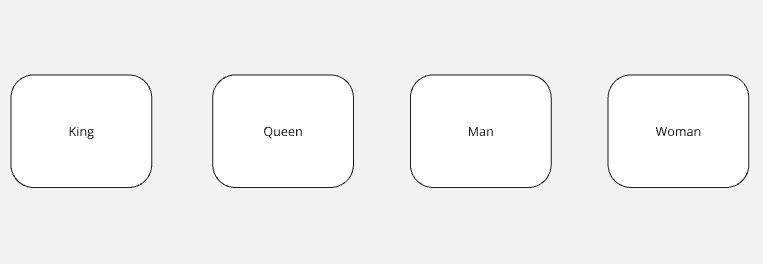
Встраивания выходят далеко за рамки числового кодирования, которое мы создали выше. Эмбеддинги позволяют нам преобразовывать большие наборы данных в более сложные матрицы, которые вы или я не смогли бы понять без тщательного анализа.
С помощью вкраплений искусственный интеллект может анализировать эти данные и применять формулы для поиска взаимосвязей. Король и королева – схожие понятия. Оба этих объекта будут иметь похожие векторы, потому что их понятия почти идентичны.
С помощью векторов мы действительно можем заниматься математикой. У машин это получается гораздо лучше, чем у нас. Машина может рассматривать их отношения с помощью формулы, которую вы видите ниже.
Король - мужчина + женщина = королева
Контролируемые и неконтролируемые вкрапления
Существует два основных типа вкраплений: Supervised и Unsupervised.
Контролируемые вкрапления
Если мы обучаем модель на структурированных данных с метками и сопоставлениями, это называется супервизорным обучением и генерирует супервизорные вкрапления. ИИ явно обучает человек.
Общее использование
- Электронная почта: Определенные типы электронной почты отображаются как спам или не спам.
- Изображения: Модель обучается на маркированных изображениях кошек и собак.
При использовании Supervised Embeddings человек уже знает о шаблоне и обучает ему машину.
Неподконтрольные вкрапления

Неподконтрольные вкрапления являются неструктурированными и немаркированными. Модель сканирует огромные массивы данных. Затем она объединяет в группы слова и символы, которые часто встречаются вместе. Это позволяет модели обнаруживать закономерности, а не узнавать их непосредственно от человека. При достаточном количестве открытий эти закономерности могут привести к предсказаниям.
Общее использование
- LLM: Большие языковые модели предназначены для сканирования больших массивов слов и точного предсказания их сочетаемости.
- Автозаполнение и проверка орфографии: Более примитивная форма этой же концепции. Она предназначена для точного предсказания символов, из которых состоят слова.
Как создаются вкрапления
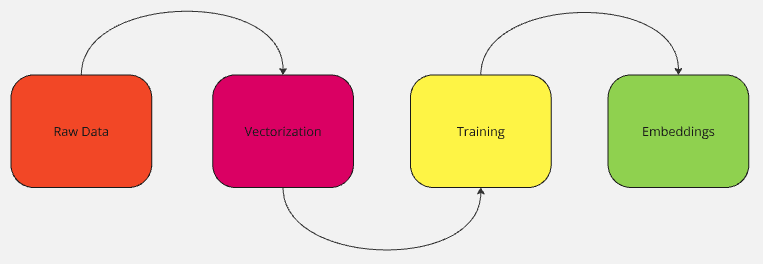
Встраивания не просто назначаются человеком, они изучаются. Чтобы узнать сходства, закономерности и, в конечном счете, взаимосвязи, модель должна быть обучена на большом количестве данных.
Шаг 1: Сбор данных
Для обучения модели необходим большой набор данных. Если вы обучите свою модель на Википедии, она будет узнавать факты из Википедии и говорить как Википедия. Наш API Web Scraper поможет вам извлекать высококачественные данные в режиме реального времени.
Вы можете обучить свою модель практически на всем.
- Текст: Книги, PDF-файлы, веб-сайты и т. д.
- Изображения: Маркированные изображения, отношения пикселей
- Взаимодействие с пользователями: Рекомендации по продуктам, поведение браузера
Шаг 2: Преобразование данных в векторы
Как мы узнали ранее, машины не очень хорошо работают с данными, читаемыми человеком. Данные, полученные на предыдущем этапе, необходимо преобразовать в числовые векторы.
Существует два типа кодирования:
- Одногорячее кодирование: Этот метод является более базовым. В этом формате модель не может отразить взаимосвязи в данных.
- Плотные вкрапления: Они чаще всего встречаются в современном ИИ. Близко связанные объекты (король и королева) группируются в матрице вплотную друг к другу.
Шаг 3: Обучение модели
Для создания вкраплений модели используют методы машинного обучения, подобные тем, что описаны ниже.
- Совместное употребление слов(Word2Vec, GloVe
)Полиленг не изменяется
- Контекстное обучение(BERT, GPT
)Polylang placeholder do not modify
Шаг 4: Тонкая настройка
После того как модель обучена, она нуждается в тонкой настройке. Для тонкой настройки модели ее вкрапления настраиваются таким образом, чтобы они подходили для решения конкретных задач.
- Поисковые системы совершенствуют свои вкрапления, чтобы лучше понимать запросы.
- Системы рекомендаций часто корректируют свои вкрапления в зависимости от поведения пользователя.
- LLM требуют периодической тонкой настройки, чтобы корректировать свои вкрапления на основе новых данных.
Заключение
Вкрапления – неотъемлемая часть не только современной индустрии ИИ, но и всей технологической отрасли в целом. Они лежат в основе всего – от результатов поиска до LLM. С нашими наборами данных вы получаете доступ к огромному количеству хороших данных для обучения вашей модели.
Зарегистрируйтесь сейчас и начните бесплатную пробную версию, включая образцы наборов данных.





