

В этом руководстве вы увидите следующее:
- Что такое Pica и почему она отлично подходит для создания агентов ИИ, интегрирующихся с внешними инструментами.
- Почему агентам ИИ требуется интеграция со сторонними решениями для получения данных.
- Как использовать встроенный коннектор Bright Data в агенте Pica для получения веб-данных для получения более точных ответов.
Давайте погрузимся!
Что такое пика?
Pica – это платформа с открытым исходным кодом, предназначенная для быстрого создания агентов искусственного интеллекта и интеграций с SaaS. Она предоставляет упрощенный доступ к 125+ API сторонних разработчиков, не требуя управления ключами или сложных конфигураций.
Цель Pica – сделать так, чтобы модели искусственного интеллекта могли легко подключаться к внешним инструментам и сервисам. С помощью Pica вы можете настроить интеграцию всего за несколько кликов, а затем легко использовать ее в своем коде. Это позволяет рабочим процессам ИИ получать данные в режиме реального времени, работать со сложной автоматизацией и многое другое.
Проект быстро завоевал популярность на GitHub, набрав более 1300 звезд всего за несколько месяцев. Это свидетельствует о его активном развитии и принятии сообществом.
Почему агентам искусственного интеллекта нужна интеграция веб-данных
Каждый фреймворк агента ИИ наследует основные ограничения от LLM, на которых он построен. Поскольку LLM предварительно обучаются на статических наборах данных, им не хватает осведомленности о реальном времени, и они не могут получить надежный доступ к живому веб-контенту.
Это часто приводит к устаревшим ответам или даже галлюцинациям. Чтобы преодолеть эти ограничения, агентам (и LLM, от которых они зависят) необходим доступ к надежным и актуальным веб-данным. Почему именно веб-данные? Потому что Интернет остается наиболее полным и актуальным источником информации.
Именно поэтому эффективный агент ИИ должен уметь быстро и легко интегрироваться со сторонними поставщиками веб-данных ИИ. И именно здесь на помощь приходит Pica!
На платформе Pica вы найдете более 125 доступных интеграций, включая интеграцию для Bright Data:
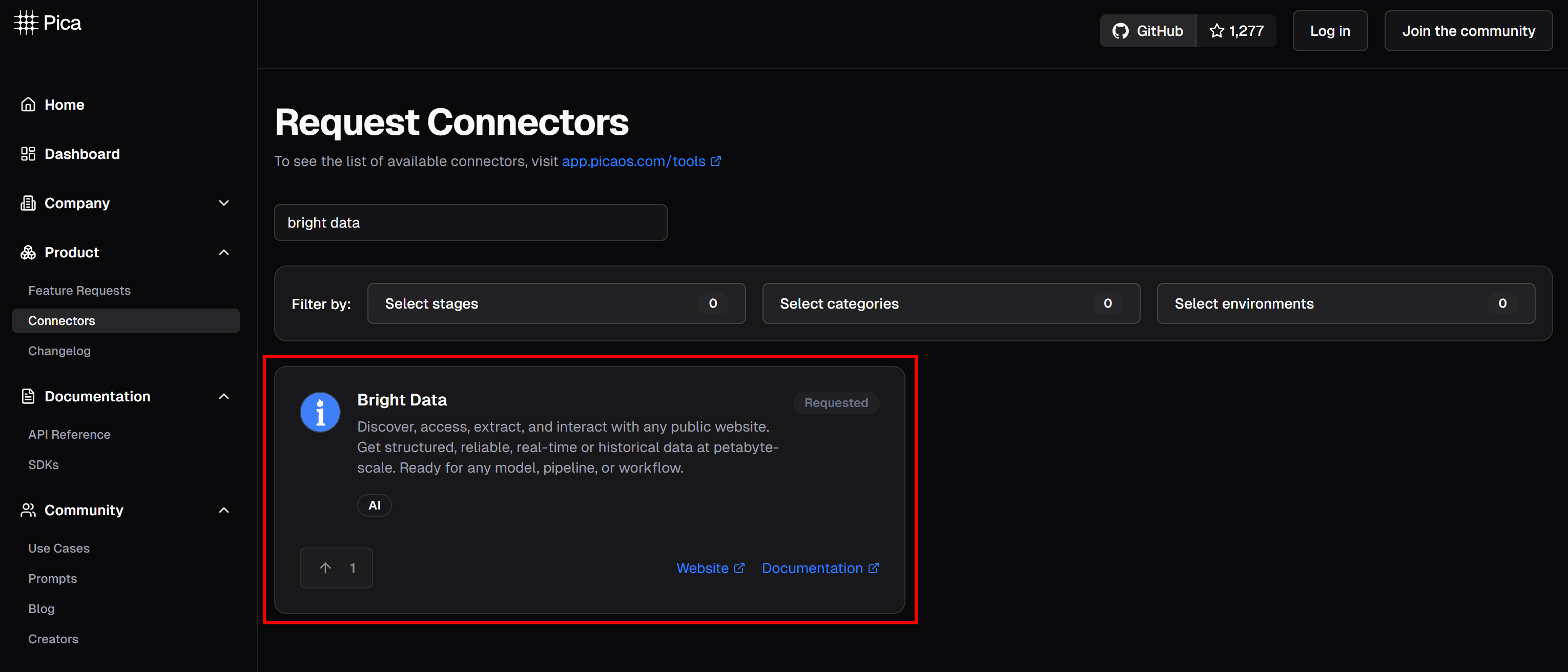
Интеграция с Bright Data позволяет вашим агентам искусственного интеллекта и рабочим процессам легко подключаться к ним:
- Web Unlocker API: Продвинутый API для скраппинга, который обходит защиту от ботов, предоставляя содержимое любой веб-страницы в формате Markdown.
- API для веб-скреперов: Специализированные решения для этичного извлечения свежих структурированных данных с таких популярных сайтов, как Amazon, LinkedIn, Instagram и 40 других.
Эти инструменты дают возможность агентам искусственного интеллекта, рабочим процессам или конвейерам подкреплять свои ответы надежными веб-данными, извлекаемыми на лету из соответствующих страниц. Посмотрите на эту интеграцию в действии в следующей главе!
Как создать агента искусственного интеллекта, который может получать данные из Сети с помощью Pica и Bright Data
В этом руководстве вы узнаете, как использовать Pica для создания агента ИИ на Python, который подключается к интеграции Bright Data. Таким образом, ваш агент сможет получать структурированные веб-данные с таких сайтов, как Amazon.
Выполните следующие шаги, чтобы создать своего агента ИИ на основе Bright Data с помощью Pica!
Пререквизиты
Чтобы следовать этому руководству, вам понадобятся:
- На вашем компьютере установлен Python 3.9 или выше (мы рекомендуем последнюю версию).
- Счет Пика.
- Ключ API Bright Data.
- Ключ API OpenAI.
Не волнуйтесь, если у вас еще нет ключа API Bright Data или учетной записи Pica. Мы покажем вам, как их установить в следующих шагах.
Шаг #1: Инициализация проекта Python
Откройте терминал и создайте новую директорию для вашего проекта агента Pica AI:
mkdir pica-bright-data-agentПапка pica-bright-data-agent будет содержать код Python для вашего агента Pica. Он будет использовать интеграцию Bright Data для получения веб-данных.
Затем перейдите в каталог проекта и создайте в нем виртуальное окружение:
cd pica-bright-data-agent
python -m venv venvТеперь откройте проект в вашей любимой среде разработки Python. Мы рекомендуем Visual Studio Code с расширением Python или PyCharm Community Edition.
В папке проекта создайте новый файл с именем agent.py. Структура каталогов должна выглядеть следующим образом:
pica-bright-data-agent/
├── venv/
└── agent.pyАктивируйте виртуальную среду в терминале. В Linux или macOS выполните команду:
source venv/bin/activateАналогично, в Windows выполните эту команду:
venv/Scripts/activateНа следующих шагах вы установите необходимые пакеты Python. Если вы предпочитаете установить все прямо сейчас, с активированной виртуальной средой, просто выполните команду:
pip install langchain langchain-openai pica-langchain python-dotenvВсе готово! Теперь у вас есть среда разработки на Python, готовая к созданию ИИ-агента с интеграцией Bright Data в Pica.
Шаг #2: Настройка переменных окружения Чтение
Ваш агент будет подключаться к сторонним сервисам, таким как Pica, Bright Data и OpenAI. Чтобы обеспечить безопасность этих интеграций, избегайте жесткого кодирования ключей API непосредственно в коде Python. Вместо этого храните их как переменные окружения.
Чтобы упростить загрузку переменных окружения, воспользуйтесь библиотекой python-dotenv. В активированной виртуальной среде установите ее с помощью:
pip install python-dotenvЗатем импортируйте библиотеку и вызовите load_dotenv() в верхней части файла agent.py, чтобы загрузить переменные окружения:
import os
from dotenv import load_dotenv
load_dotenv()Эта функция позволяет вашему скрипту считывать переменные из локального файла .env. Создайте этот .env-файл в корне каталога вашего проекта. Структура папок будет выглядеть следующим образом:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.pyОтлично! Теперь вы можете безопасно работать с ключами API и другими секретами с помощью переменных окружения.
Шаг №3: Настройка Pica
Если вы еще не сделали этого, создайте бесплатную учетную запись Pica. По умолчанию Pica сгенерирует для вас API-ключ. Вы можете использовать этот API-ключ с LangChain или любой другой поддерживаемой интеграцией.
Перейдите на страницу “Быстрый старт” и выберите вкладку “LangChain”:
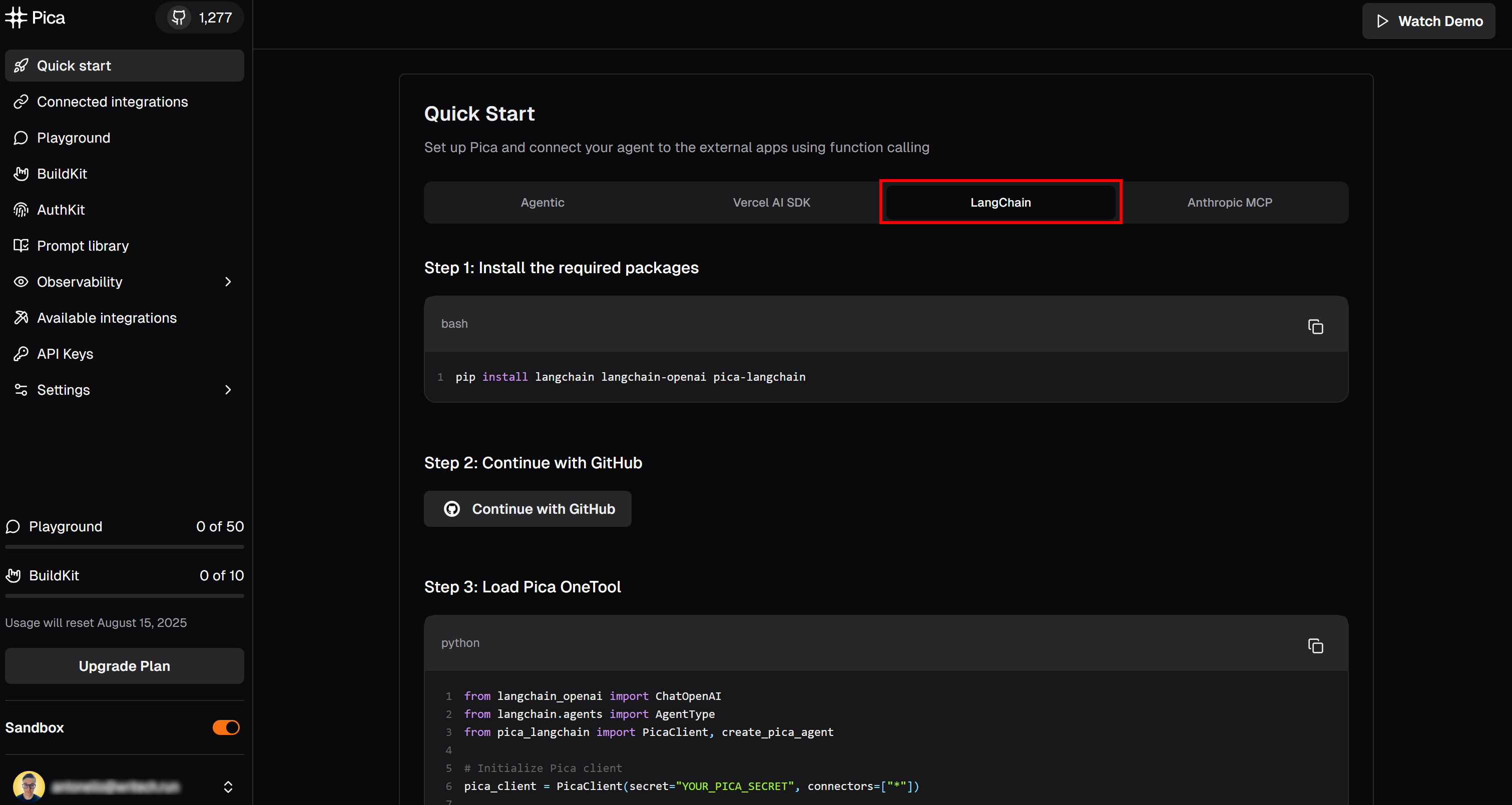
Здесь вы найдете инструкции по началу работы с Pica в LangChain. В частности, следуйте приведенной здесь команде установки. В активированной виртуальной среде запустите:
pip install langchain langchain-openai pica-langchainТеперь прокрутите страницу вниз, пока не дойдете до раздела “API-ключ”:
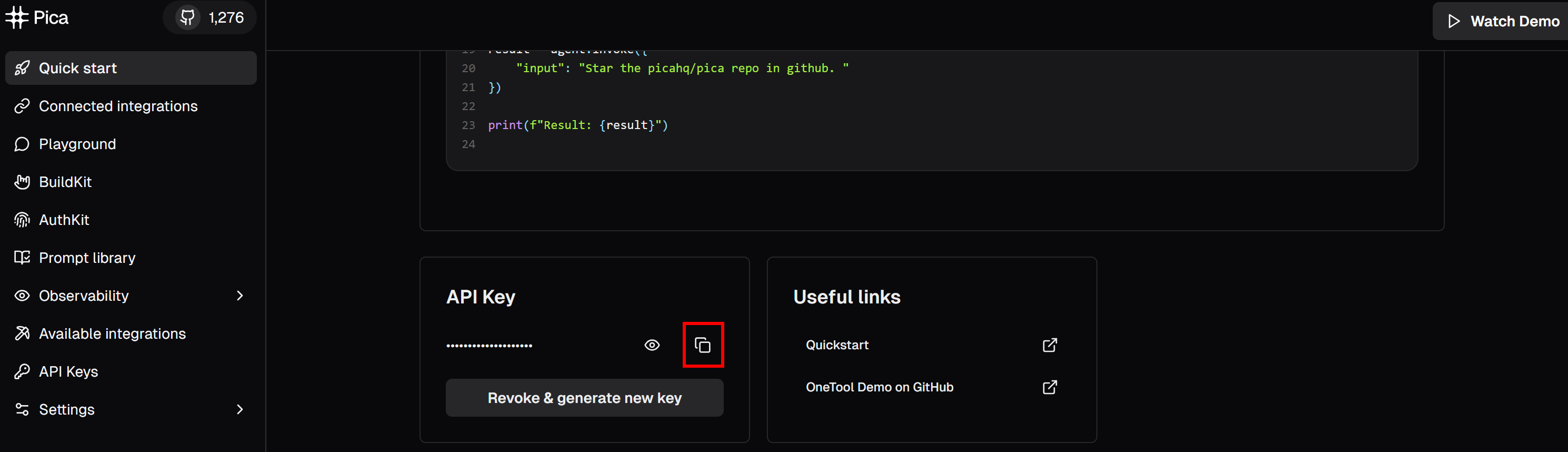
Нажмите кнопку “скопировать в буфер обмена”, чтобы скопировать ваш ключ API Pica. Затем вставьте его в файл .env, определив переменную окружения следующим образом:
PICA_API_KEY="<YOUR_PICA_KEY>"Замените на реальный ключ API, который вы только что скопировали.
Фантастика! Теперь ваш аккаунт Pica полностью настроен и готов к использованию в вашем коде.
Шаг №4: Интеграция ярких данных в Pica
Прежде чем приступить к работе, обязательно следуйте официальному руководству по настройке ключа API Bright Data. Этот ключ понадобится для подключения вашего агента к Bright Data с помощью встроенной интеграции, доступной на платформе Pica.
Теперь, когда у вас есть ключ API, вы можете добавить интеграцию Bright Data в Pica.
На вкладке “LangChain” вашей панели Pica прокрутите вниз до раздела “Последние интеграции” и нажмите кнопку “Обзор интеграций”:
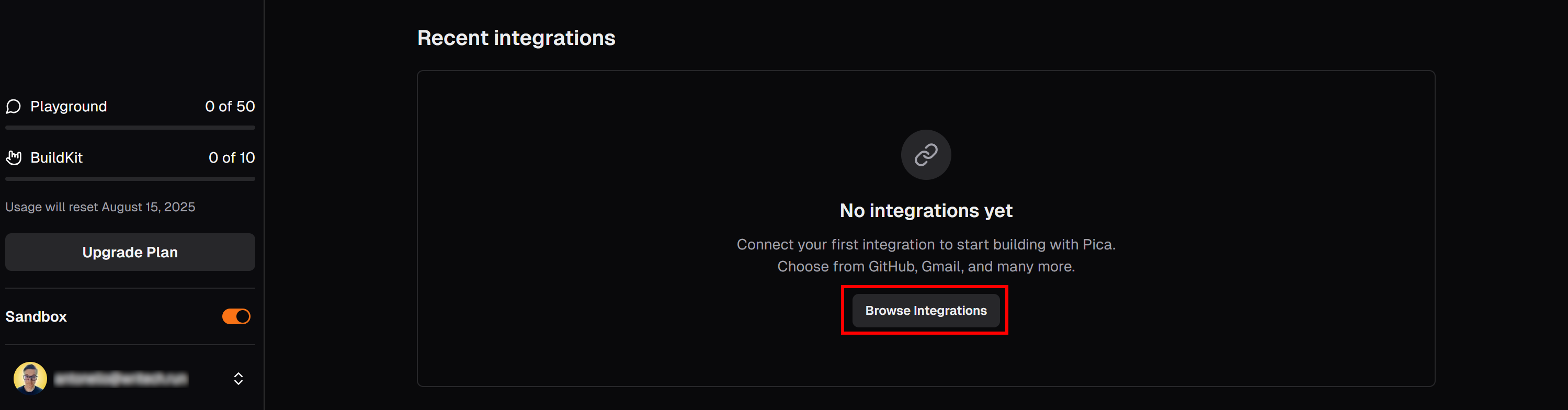
Откроется модальное окно. В строке поиска введите “brightdata” и выберите интеграцию “BrightData”:
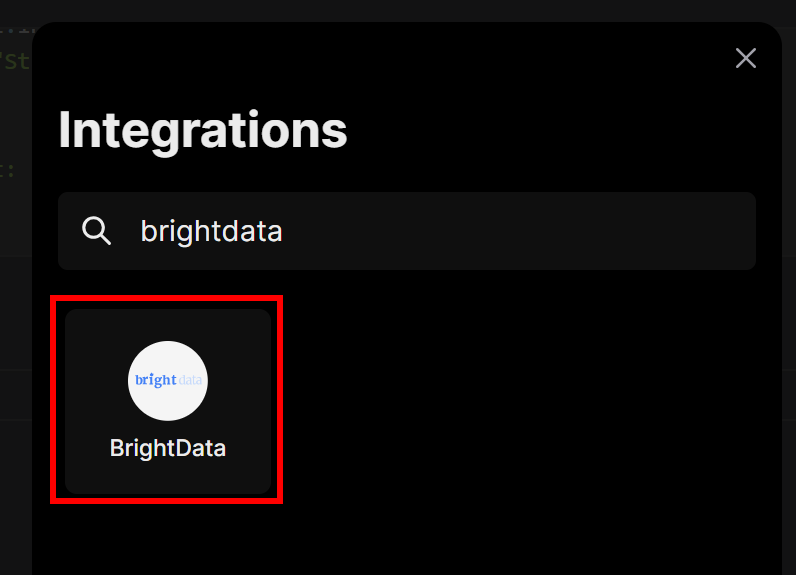
Вам будет предложено ввести API-ключ Bright Data, который вы создали ранее. Вставьте его, а затем нажмите кнопку “Подключиться”:
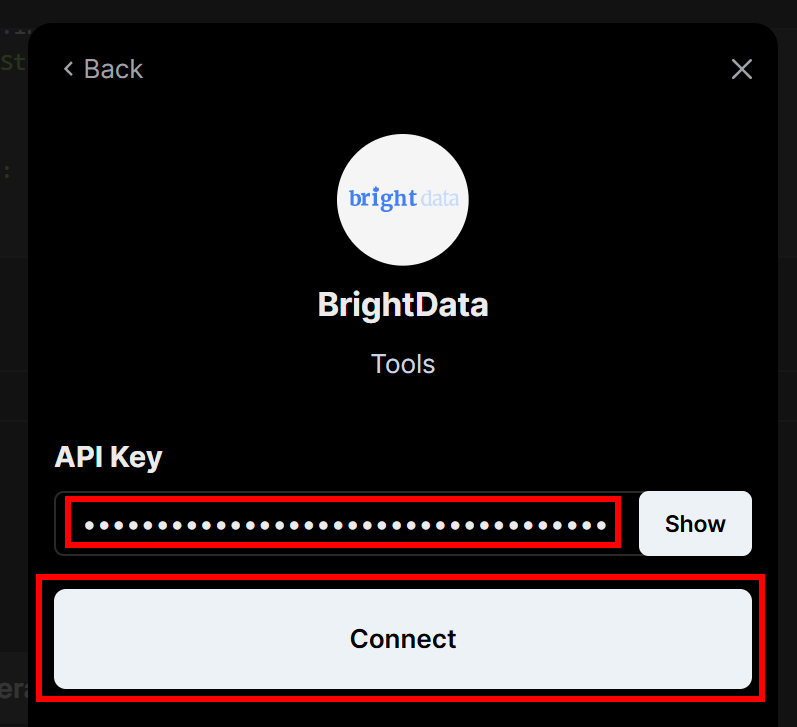
Далее в левом меню нажмите на пункт меню “Подключенные интеграции”:
На странице “Подключенные интеграции” вы должны увидеть Bright Data в списке подключенных интеграций. В таблице нажмите кнопку “Скопировать в буфер обмена”, чтобы скопировать ключ подключения:
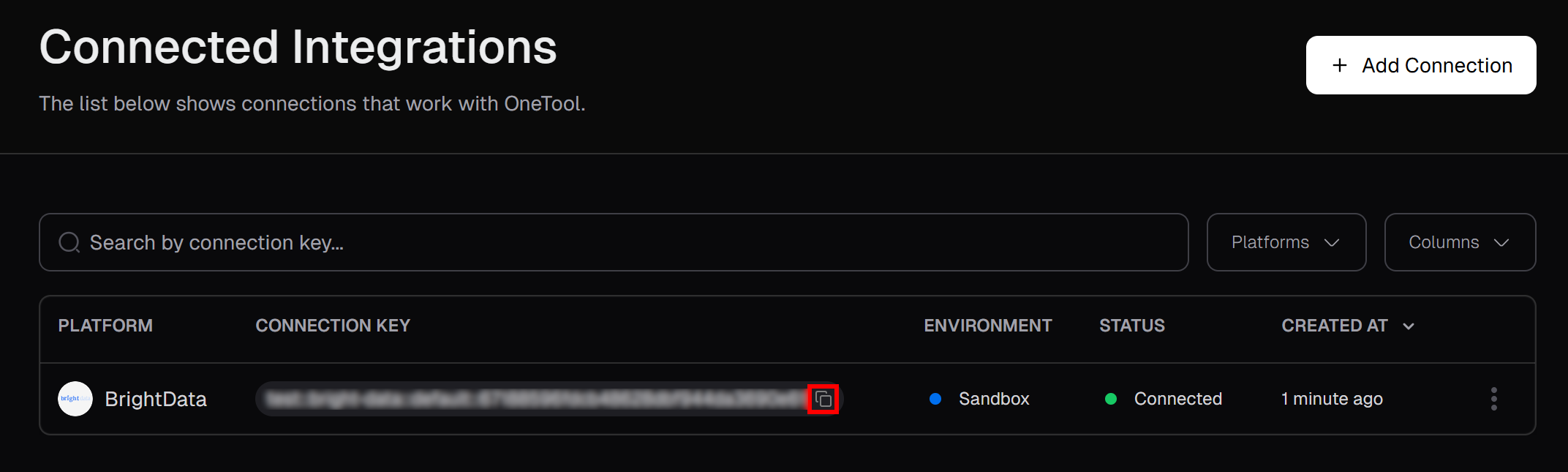
Затем вставьте его в файл .env, добавив:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"Обязательно замените на реальный ключ подключения, который вы скопировали.
Это значение понадобится вам для инициализации агента Pica в коде, чтобы он знал, что нужно загрузить настроенное соединение Bright Data. Как это сделать, смотрите в следующем шаге!
Шаг #5: Инициализация агента Pica
В файле agent.py инициализируйте агента Pica:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()В приведенном выше фрагменте инициализируется клиент Pica, подключающийся к вашей учетной записи Pica с использованием секрета PICA_API_KEY, загруженного из вашего окружения. Кроме того, он выбирает интеграцию Bright Data, которую вы настроили ранее, из всех доступных коннекторов.
Это означает, что все агенты искусственного интеллекта, которые вы создадите с помощью этого клиента, смогут использовать возможности Bright Data по поиску веб-данных в режиме реального времени.
Не забудьте импортировать необходимые классы:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptionsПотрясающе! Вы готовы приступить к интеграции LLM.
Шаг №6: Интеграция OpenAI
Вашему агенту Pica потребуется LLM-движок, чтобы понимать входные подсказки и выполнять необходимые задачи, используя возможности Bright Data.
В этом руководстве используется интеграция OpenAI, поэтому вы определите LLM для своего агента в файле agent.py следующим образом:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Обратите внимание, что во всех примерах Pica LangChain в документации используется температура=0. Это обеспечивает детерминированность модели, которая всегда выдает один и тот же результат на один и тот же вход.
Помните, что класс ChatOpenAI происходит из этого импорта:
from langchain_openai import ChatOpenAIВ частности, ChatOpenAI ожидает, что ваш ключ OpenAI API будет определен в переменной окружения OPENAI_API_KEY. Поэтому в вашем файле .env добавьте:
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>Замените на ваш реальный ключ OpenAI API.
Потрясающе! Теперь у вас есть все строительные блоки для создания агента Pica AI.
Шаг №7: Определите своего агента по пике
В Pica агент искусственного интеллекта состоит из трех основных частей:
- Экземпляр клиента Pica
- Двигатель LLM
- Тип агента Pica
В этом случае вы хотите создать агента искусственного интеллекта, который сможет вызывать функции OpenAI (которые, в свою очередь, подключаются к возможностям веб-поиска Bright Data через интеграцию Pica). Таким образом, создайте своего агента Pica следующим образом:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) Не забудьте добавить необходимые импорты:
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeВеликолепно! Теперь осталось протестировать агента на задаче поиска данных.
Шаг #8: Допросите своего агента искусственного интеллекта
Чтобы убедиться в том, что интеграция Bright Data работает в вашем агенте Pica, поставьте перед ним задачу, которую он обычно не может выполнить самостоятельно. Например, попросите его получить обновленные данные с недавней страницы товара на Amazon, например Nintendo Switch 2 (доступна на https://www.amazon.com/dp/B0F3GWXLTS/).
Для этого вызовите своего агента с помощью этих данных:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})Примечание: подсказка намеренно явная. Она точно указывает агенту, что делать, какую страницу соскребать и какую интеграцию использовать. Это гарантирует, что LLM будет использовать инструменты Bright Data, настроенные через Pica, и получит ожидаемые результаты.
Наконец, выведите на печать результаты работы агента:
print(f"nAgent Result:n{result}")И с этой последней строчкой ваш агент Pica AI завершен. Пора посмотреть, как все это будет выглядеть в действии!
Шаг № 9: Соберите все вместе
Теперь ваш файл agent.py должен содержать:
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")Как видите, менее чем за 50 строк кода вы создали агента Pica с мощными возможностями получения данных. Это стало возможным благодаря интеграции Bright Data, доступной непосредственно на платформе Pica.
Запустите своего агента с помощью:
python agent.pyВ терминале вы должны увидеть журналы, похожие на следующие:
# Omitted for brevity...
2025-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2025-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2025-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2025-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2025-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2025-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2025-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2025-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2025-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2025-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2025-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2025-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2025-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataПроще говоря, это то, что сделал ваш агент Pica:
- Подключитесь к Pica и извлеките настроенную интеграцию Bright Data.
- Обнаружил, что на платформе Bright Data доступно 54 инструмента.
- Извлеките список всех наборов данных из Bright Data.
- По вашей подсказке он выбрал инструмент “Trigger Synchronous Web Scraping and Retrieve Results” и использовал его для соскабливания свежих данных с указанной страницы продукта Amazon. За кулисами это запускает вызов Bright Data Amazon Scraper, передавая URL-адрес продукта Amazon. Скрепер получит и вернет данные о продукте.
- Успешно выполнили действие скраппинга и вернули данные.
Ваш вывод должен выглядеть примерно так:

Вставьте этот вывод в редактор Markdown, и вы увидите хорошо отформатированный отчет о продукте:
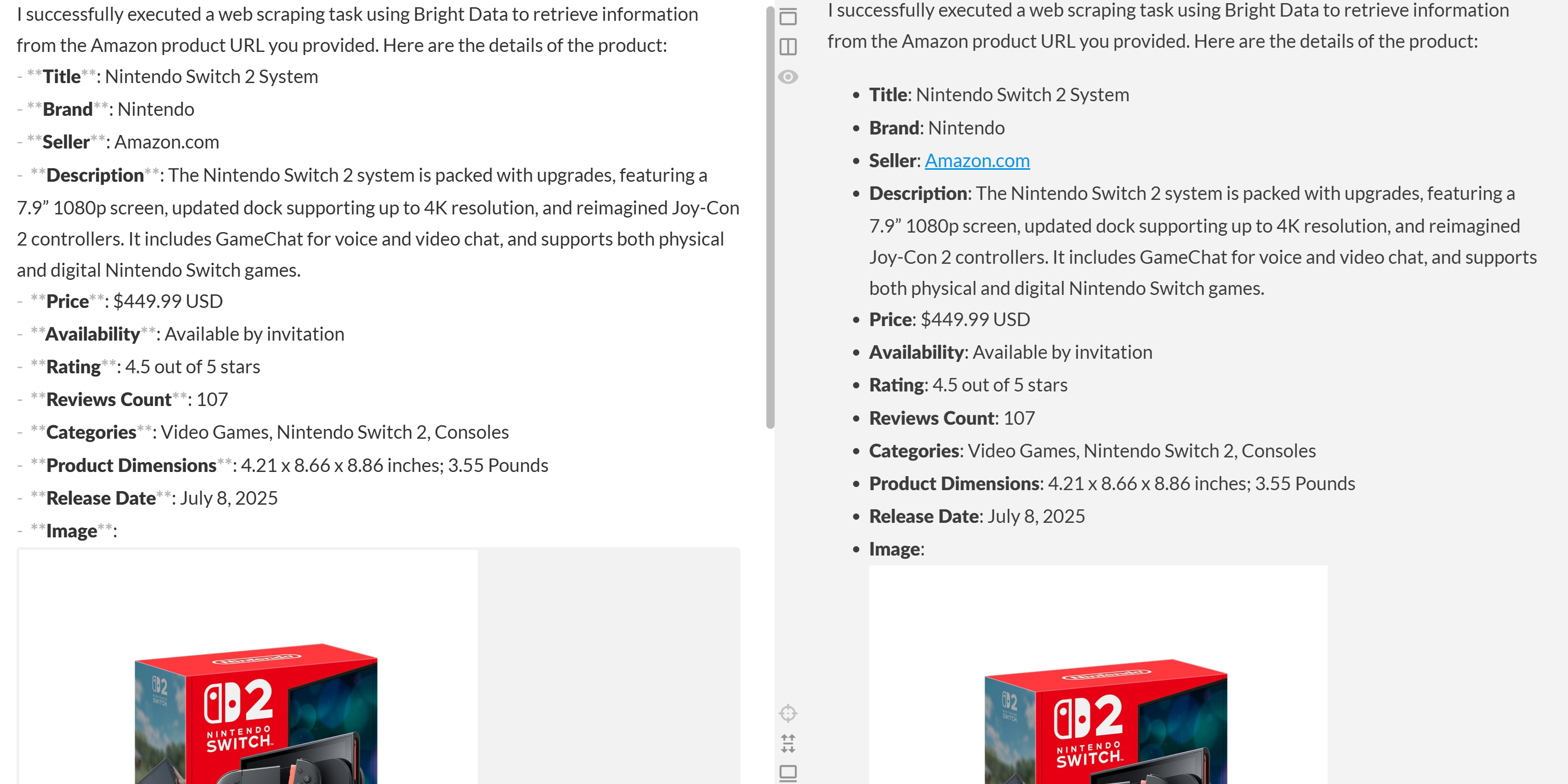
Как вы можете видеть, агент смог создать отчет в формате Markdown, содержащий значимые и актуальные данные со страницы товара Amazon. Вы можете убедиться в точности, посетив целевую страницу товара в браузере:
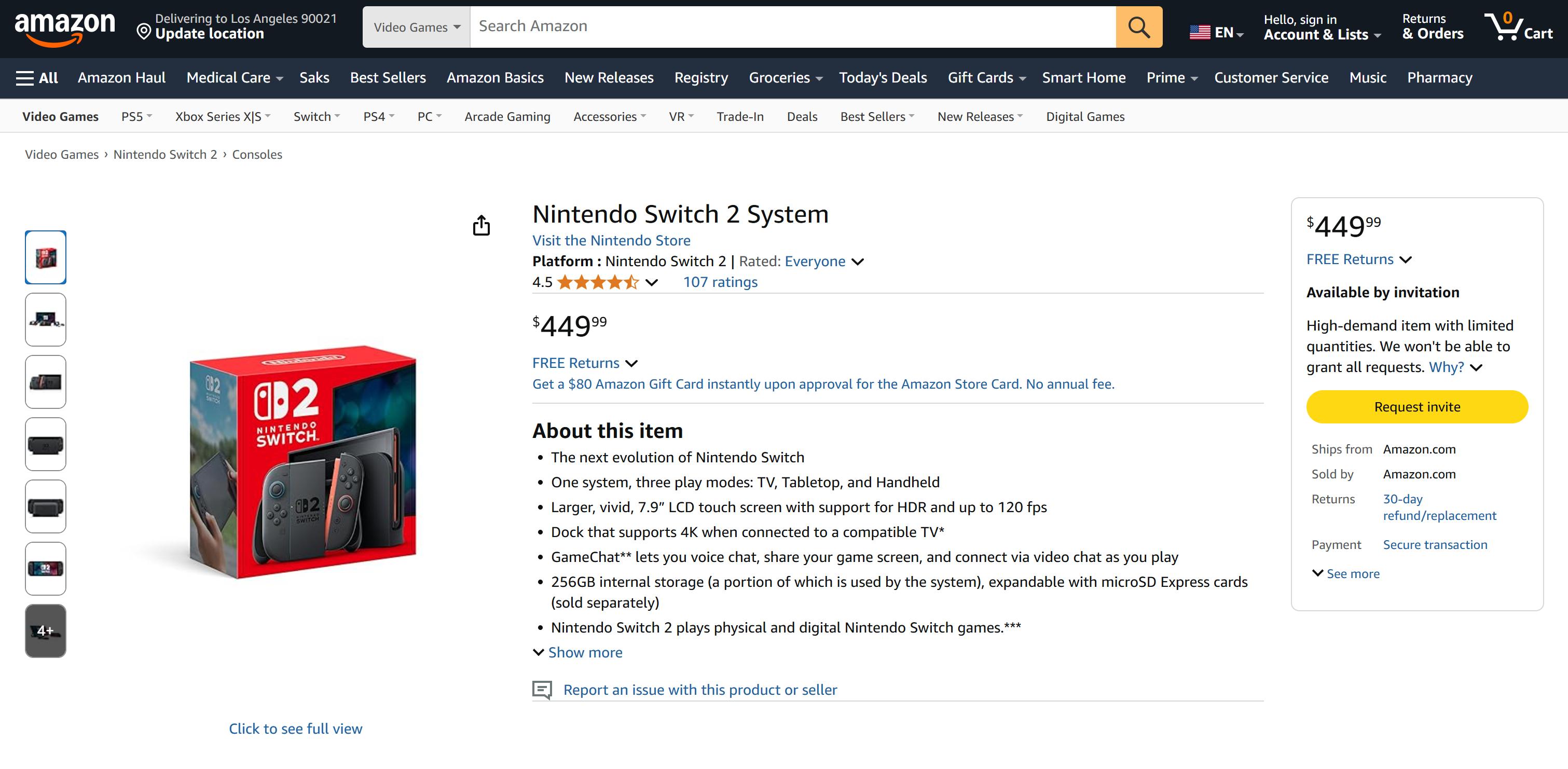
Обратите внимание, что полученные данные – это реальные данные со страницы Amazon, а не галлюцинации LLM. Это свидетельствует о том, что скраппинг выполнен с помощью инструментов Bright Data. И это только начало!
Благодаря широкому спектру действий Bright Data, доступных в Pica, ваш агент теперь может получать данные практически с любого веб-сайта. В том числе и с таких сложных сайтов, как Amazon, которые известны строгими мерами по борьбе со скаппингом (например, пресловутой Amazon CAPTCHA).
И вуаля! Вы только что испытали бесшовный веб-скраппинг с помощью интеграции Bright Data в агента Pica AI.
Заключение
В этой статье вы узнали, как использовать Pica для создания агента искусственного интеллекта, который может подкреплять свои ответы свежими веб-данными. Это стало возможным благодаря встроенной интеграции Pica с Bright Data. Коннектор Pica Bright Data дает ИИ возможность получать данные с любой веб-страницы.
Помните, что это был всего лишь простой пример. Если вы хотите создать более сложные агенты, вам понадобятся надежные решения для получения, проверки и преобразования живых веб-данных. Именно это вы найдете в инфраструктуре Bright Data AI.
Создайте бесплатную учетную запись Bright Data и начните изучать наши инструменты для извлечения веб-данных с поддержкой искусственного интеллекта!





