Thanks to its extensive libraries and tools, PHP is a great language for building web scrapers. Designed specifically for web development, PHP handles web scraping tasks with ease and reliability.
There are many different methods for scraping websites using PHP, and you’ll explore a few different methods in this article. Specifically, you’ll learn how to scrape websites using curl, file_get_contents, Symfony BrowserKit, and Symfony’s Panther component. Additionally, you’ll learn about some common challenges you may face during web scraping and how to avoid them.
In this section, you’ll learn a few commonly used methods of web scraping both basic and complex/dynamic sites.
Please note: While we cover various methods in this tutorial, this is by no means an exhaustive list.
Prerequisites
To follow along with this tutorial, you need the latest version of PHP and Composer, a dependency manager for PHP. This article was tested using PHP 8.1.18 and Composer 2.5.5.
Once PHP and Composer are set up, create a directory named php-web-scraping and cd into it:
mkdir php-web-scraping
cd $_
You’ll work in this directory for the rest of the tutorial.
curl
curl is a near-ubiquitous low-level library and CLI tool written in C. It can be used to fetch the contents of a web page using HTTP or HTTPS. In almost all platforms, PHP comes with curl support enabled out of the box.
In this section, you’ll scrape a very basic web page that lists countries by population based on estimates by the United Nations. You’ll extract the links in the menu along with the link texts.
To start, create a file called curl.php and then initialize curl in that file with the curl_init function:
<?php
$ch = curl_init();
Then set the options for fetching the web page. This includes setting the URL and the HTTP method (GET, POST, etc.) using the function curl_setopt:
In this code, you set the target URL to the web page and the method to GET. The CURLOPT_RETURNTRANSFER tells curl to return the HTML response.
Once curl is ready, you can make the request using curl_exec:
$response = curl_exec($ch);
Fetching the HTML data is only the first step in web scraping. To extract data from the HTML response, you need to use several techniques. The simplest method is to use regular expressions for very basic HTML extraction. However, please note that you can’t parse arbitrary HTML with regex, but for very simple parsing, regex is enough.
For example, extract the <a> tags, which have href and title attributes and contain a <span>:
Then release the resources by using the curl_close function:
curl_close($ch);
Run the code with the following:
php curl.php
You should see that it correctly extracts the links:
curl gives you very low-level control over how a web page is fetched over HTTP/HTTPS. You can fine-tune the different connection properties and even add additional measures, such as proxy servers (more on this later), user agents, and timeouts.
Additionally, curl is installed by default in most operating systems, which makes it a great choice for writing a cross-platform web scraper.
However, as you saw, curl is not enough on its own, and you need an HTML parser to properly scrape data. curl also can’t execute JavaScript on a web page, which means you can’t scrape dynamic web pages and single-page applications (SPAs) with curl.
file_get_contents
The file_get_contents function is primarily used for reading the contents of a file. However, by passing an HTTP URL, you can fetch HTML data from a web page. This means file_get_contents can replace the usage of curl in the previous code.
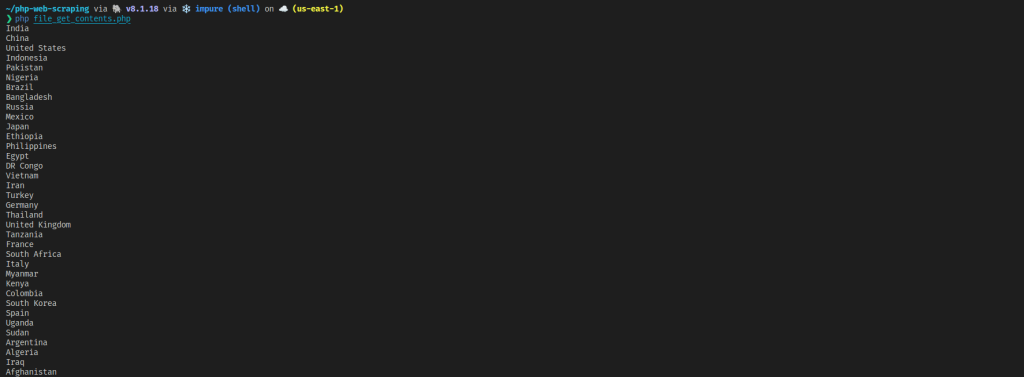
In this section, you’ll scrape the same page as before, but this time, the scraper will be more advanced, and you’ll be able to extract the names of all the countries from the table.
Create a file named file_get-contents.php and start by passing a URL to file_get_contents:
The $html variable now holds the HTML code of the web page.
Similar to the previous example, fetching the HTML data is just the first step. To spice things up, use libxml to select elements using XPath selectors. To do that, you first need to initialize a DOMDocument and load the HTML into it:
$doc = new DOMDocument;
libxml_use_internal_errors(true);
$doc->loadHTML($html);
libxml_clear_errors();
Here, you select the countries in the following order: the first tbody element, a tr element inside the tbody, the first td in the tr element, and an a with a title attribute inside the td element.
The following code initializes a DOMXpath class and uses evaluate to select the element using the XPath selector:
$xpath = new DOMXpath($doc);
$countries = $xpath->evaluate('(//tbody)[1]/tr/td[1]//a[@title=true()]');
All that is left is to loop over the elements and print the text:
foreach($countries as $country) {
echo $country->textContent . "\n";
}
Run the code with the following:
php file_get_contents.php
As you can see, file_get_contents is simpler to use than curl and is often used to quickly fetch the HTML code of a web page. However, it suffers the same drawbacks as curl—you need an additional HTML parser, and you can’t scrape dynamic web pages and SPAs. Additionally, you lose the fine-tuned controls provided by curl. However, its simplicity makes it a good choice for scraping basic static sites.
Symfony BrowserKit
Symfony BrowserKit is a component of the Symfony framework that simulates the behavior of a real browser. This means you can interact with the web page like in an actual browser; for example, clicking on buttons/links, submitting forms, and going back and forward in history.
In this section, you’ll visit the Bright Data blog, enter PHP in the search box, and submit the search form. Then you’ll scrape the article names from the result:
To use Symfony BrowserKit, you must install the BrowserKit component with Composer:
composer require symfony/browser-kit
You also need to install the HttpClient component to make HTTP requests over the internet:
composer require symfony/http-client
BrowserKit supports selecting elements using XPath selectors by default. In this example, you use CSS selectors. For that, you need to install the CssSelector component as well:
composer require symfony/css-selector
Create a file named symfony-browserkit.php. In this file, initialize HttpBrowser:
<?php
require "vendor/autoload.php";
use Symfony\Component\BrowserKit\HttpBrowser;
$client = new HttpBrowser();
To select the form where the search button is, you need to select the button itself and use the form function to get the enclosing form. The button can be selected with the filter function by passing its ID. Once the form is selected, you can submit it using the submit function of the Httpbrowser class.
By passing a hash of the values of the inputs, the submit function can fill up the form before it’s submitted. In the following code, the input with the name q has been given the value PHP, which is the same as typing PHP into the search box:
While Symfony BrowserKit is a step up from the previous two methods in terms of interacting with web pages, it’s still limited because it can’t execute JavaScript. This means you can’t scrape dynamic websites and SPAs using BrowserKit.
Symfony Panther
Symfony Panther is another Symfony component that wraps around the BrowserKit component. However, Symfony Panther offers one major advantage: instead of simulating a browser, it executes the code in an actual browser using the WebDriver protocol to remotely control a real browser. This means you can scrape any website, including dynamic websites and SPAs.
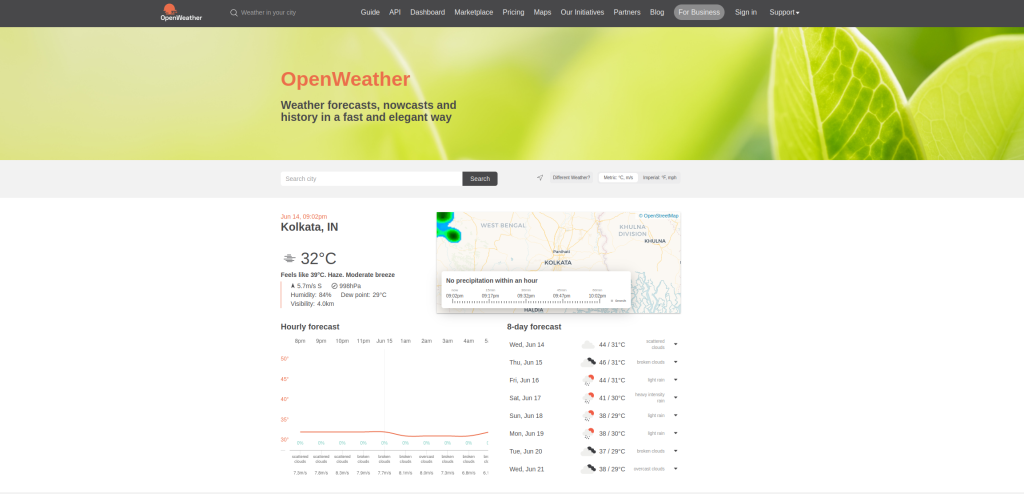
In this section, you’ll load the OpenWeather home page, type the name of your city in the search box, perform the search, and scrape the current weather of your city:
To get started, install Symfony Panther with Composer:
composer require symfony/panther
You also need to install dbrekelmans/browser-driver-installer, which can automatically detect the installed browser on your system and install the correct driver for it. Make sure you have either a Firefox- or a Chromium-based browser installed in your system:
composer require dbrekelmans/bdi
To install the appropriate driver in the drivers directory, run the bdi tool:
vendor/bin/bdi detect drivers
Create a file named symfony-panther.php and start by initializing a Panther client:
<?php
require 'vendor/autoload.php';
use Symfony\Component\Panther\Client;
$client = Client::createFirefoxClient();
Note: Depending on your browser, you may need to use createChromeClient or createSeleniumClient instead of createFirefoxClient.
Because Panther uses Symfony BrowserKit behind the scenes, the next codes are very similar to the code in the Symfony BrowserKit section.
You start by loading the web page using the request function. When the page loads, it’s initially covered by a div with the owm-loader class, which shows the loading progress bar. You need to wait for this div to disappear before you start interacting with the page. This can be done using the waitForStaleness function, which takes a CSS selector and waits for it to be removed from the DOM.
After the loading bar is removed, you need to accept the cookies so that the cookies banner is closed. For that, the selectButton function comes in handy, as it can search a button by its text. Once you have the button, the click function performs a click on it:
Note: Depending on how fast the page loads, the loading bar may disappear before the waitForStaleness function runs. This throws an exception. That’s why that line has been wrapped in a try-catch block.
Now it’s time to type Kolkata into the search bar. Select the search bar with the filter function and use the sendKeys function to provide input to the search bar. Then click on the Search button:
Once the button is selected, an autocomplete suggestion box pops up. You can use the waitForVisibility function to wait until the list is visible and then click on the first item using the combination of filter and click as before:
Here, you’re waiting for the element with selector .orange-text+h2 to contain Kolkata. This indicates that the results have been loaded.
Run the code with the following:
php symfony-panther.php
Your output looks like this:
Web Scraping Challenges and Possible Solutions
Even though PHP makes it easy to write web scrapers, navigating real-life scraping projects can be complex. Numerous situations can arise, presenting challenges that need to be addressed. These challenges may stem from factors such as the structure of the data (eg pagination) or antibot measures taken by the owners of the website (eg honeypot traps).
In this section, you’ll learn about some common challenges and how to combat them.
Navigating through Paginated Websites
When scraping almost any real-life website, it’s likely that you’ll come across a situation where all the data isn’t loaded at once. Or in other words, the data is paginated. There can be two types of pagination:
All the pages are located at separate URLs. The page number is passed through a query parameter or a path parameter. For example, example.com?page=3 or example.com/page/3.
The new pages are loaded using JavaScript when the Next button is selected.
In the first scenario, you can load the pages in a loop and scrape them as separate web pages. For instance, using file_get_contents, the following code scrapes the first ten pages of an example site:
for($page = 1; $page <= 10; $page++) {
$html = file_get_contents('https://example.com/page/{$page}');
// DO the scraping
}
In the second scenario, you need to use a solution that can execute JavaScript, like Symfony Panther. In this example, you need to click on the appropriate button that loads the next page. Don’t forget to wait a little while for the new page to load:
for($page = 1; $page <= 10; $page++>) {
// Do the scraping
// Load the next page
$crawler->selectButton("Next")->click();
$client->waitForElementToContain(".current-page", $page+1)
}
Note: You should substitute appropriate waiting logic that makes sense for the particular website that you’re scraping.
Rotating Proxies
A proxy server acts as an intermediary between your computer and the target web server. It prevents the web server from seeing your IP address, thus preserving your anonymity.
However, you shouldn’t rely on one single proxy server since it can be banned. Instead, you need to use multiple proxy servers and rotate through them. The following code provides a very basic solution where an array of proxies is used and one of them is chosen at random:
CAPTCHAs are used by many websites to ensure the user is a human and not a bot. Unfortunately, this means your web scraper can get caught.
CAPTCHAs can be very primitive, like a simple checkbox asking, “Are you human?” Or they can use a more advanced algorithm, like Google’s reCAPTCHA or hCaptcha. You can probably get away with primitive CAPTCHAs using basic web page manipulation (eg checking a checkbox), but to battle advanced CAPTCHAs, you need a dedicated tool like 2Captcha. 2Captcha uses humans to solve CAPTCHAs. You simply need to pass the required details to the 2Captcha API, and it returns the solved CAPTCHA.
To get started with 2Captcha, you need to create an account and get an API key.
Install 2Captcha with Composer:
composer require 2captcha/2captcha
In your code, create an instance of TwoCaptcha:
$solver = new \TwoCaptcha\TwoCaptcha('YOUR_API_KEY');
Honeypot traps are an antibot measure that mimics a service or network to lure in scrapers and crawlers to divert them from the actual target. Although honeypots are useful for prevention against bot attacks, they can be problematic for web scraping. You don’t want your scraper to get stuck in a honeypot.
There are all kinds of measures you can take to avoid being lured into a honeypot trap. For instance, honeypot links are often hidden so that a real user doesn’t see them, but a bot can pick them up. To avoid the trap, you can try to avoid clicking on hidden links (links with display: none or visibility: none CSS properties).
Another option is to rotate proxies so that if one of the proxy server IP addresses is caught in the honeypot and banned, you can still connect through other proxies.
Conclusion
Thanks to PHP’s superior library and frameworks, making a web scraper is easy. In this article, you learned how to do the following:
Scrape a static website using curl and regex
Scrape a static website using file_get_contents and libxml
Scrape a static site using Symfony BrowserKit and submit forms
Scrape a complex dynamic site using Symfony Panther
Unfortunately, while scraping using these methods, you learned that scraping with PHP comes with added complexities. For instance, you may need to arrange for multiple proxies and carefully construct your scraper to avoid honeypots.
And this is where Bright Data comes in…
About Bright Data proxies:
Residential proxies: With over 72 million real IPs from 195 countries, Bright Data’s residential proxies enable you to access any website content regardless of location, while avoiding IP bans and CAPTCHAs.
ISP proxies: With over 700,000 ISP IPs, leverage real static IPs from any city in the world, assigned by ISPs and leased to Bright Data for your exclusive use, for as long as you require.
Datacenter proxies: With over 770,000 datacenter IPs, Bright Data’s datacenter proxy network is built of multiple IP types across the world, in a shared IP pool or for individual purchase.
Mobile proxies: With over 7 million mobile IPs, Bright Data’s advanced Mobile IP Network offers the fastest and largest real-peer 3G/4G/5G IPs network in the world.
Join the largest proxy network and get a free proxies trial.