

TL:DR: Давайте узнаем, как создать парсер Yahoo Finance для извлечения данных об акциях, чтобы выполнить финансовый анализ для торговли и инвестирования.
В этом руководстве будет рассмотрено:
- Зачем собирать финансовые данные из Интернета?
- Библиотеки и инструменты парсинга финансов
- Парсинг биржевых данных из Yahoo Finance с помощью Selenium
Зачем собирать финансовые данные из Интернета?
Парсинг финансовых данных из Интернета позволяет получить ценные сведения, которые могут пригодиться в различных сценариях:
- Автоматическая торговля. Собирая рыночные данные в реальном времени или за прошлые периоды, такие как цены и объемы акций, разработчики могут создавать автоматизированные торговые стратегии.
- Технический анализ. Исторические рыночные данные и индикаторы важны для технических аналитиков. Они позволяют выявлять закономерности и тенденции, помогая принимать инвестиционные решения.
- Финансовое моделирование. Исследователи и аналитики могут собирать данные, такие как финансовые отчеты и экономические показатели, для создания сложных моделей с целью оценки эффективности компании и инвестиционных возможностей, прогнозирования доходов.
- Исследование рынка. Финансовые данные предоставляют большой объем информации об акциях, рыночных индексах и сырьевых товарах. Анализ этих данных помогает исследователям понять тенденции рынка, настроения и состояние отрасли для принятия обоснованных инвестиционных решений.
Когда речь идет о мониторинге рынка, Yahoo Finance является одним из самых популярных финансовых сайтов. Он предоставляет инвесторам и трейдерам широкий спектр информации и инструментов: текущие и исторические данные по акциям, облигациям, взаимным фондам, товарам, валютам и рыночным индексам. Кроме того, он предлагает новостные статьи, финансовые отчеты, оценки аналитиков, диаграммы и другие ценные ресурсы.
Путем парсинга Yahoo Finance вы можете получить доступ к огромному количеству информации, необходимой для проведения финансового анализа, исследований и принятия решений.
Библиотеки и инструменты парсинга финансов
Python считается одним из лучших языков для парсинга благодаря своему синтаксису, простоте использования и богатой экосистеме библиотек. Ознакомьтесь с нашим руководством по парсингу веб-страниц с помощью Python.
Чтобы выбрать подходящую библиотеку парсинга из множества доступных, изучите Yahoo Finance в своем браузере. Вы заметите, что большая часть данных на сайте обновляется в режиме реального времени или изменяется после взаимодействия. Это означает, что сайт активно использует AJAX для динамической загрузки и обновления данных, не требуя перезагрузки страницы. Другими словами, вам нужен инструмент, который может запускать JavaScript.
Selenium позволяет парсить динамические сайты на Python. Он отображает его в браузерах, программно выполняя над ними операции, даже если они используют JavaScript для рендеринга или извлечения данных.
Благодаря Selenium вы сможете парсить целевой сайт с помощью Python. Давайте узнаем, как это сделать
Парсинг биржевых данных из Yahoo Finance с помощью Selenium
Следуйте этому пошаговому руководству и узнайте, как создать скрипт Python для парсинга веб-страниц Yahoo Finance.
Шаг 1: Установка
Прежде чем приступить к парсингу финансов, убедитесь, что вы выполнили следующие условия:
- На вашем ПК установлен Python 3+: Скачайте программу установки, дважды щелкните по ней и следуйте указаниям мастера установки.
- Python IDE на ваш выбор: PyCharm Community Edition или Visual Studio Code с расширением Python.
Затем используйте приведенные ниже команды для настройки проекта Python с виртуальной средой:
mkdir yahoo-finance-scraper
cd yahoo-finance-scraper
python -m venv envОни инициализируют папку проекта yahoo-finance-scraper. Внутри добавьте файл scraper.py, как показано ниже:
print('Hello, World!')Здесь вы добавите логику для парсинга Yahoo Finance. Сейчас это пример скрипта, который печатает только “Hello, World!”.
Запустите его, чтобы убедиться, что он работает:
python scraper.pyВ терминале вы должны увидеть:
Hello, World!Отлично, теперь у вас есть проект Python для вашего финансового парсера. Осталось добавить зависимости проекта. Установите Selenium и Webdriver Manager с помощью следующей команды терминала:
pip install selenium webdriver-managerДля этого может потребоваться немного времени, так что наберитесь терпения.
webdriver-manager не является обязательным. Тем не менее его лучше использовать, поскольку он упрощает управление веб-драйверами в Selenium. Благодаря этому вам не придется вручную загружать, настраивать и импортировать веб-драйвер.
Обновление scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# scraping logic...
# close the browser and free up the resources
driver.quit()Этот скрипт просто создает экземпляр ChromeWebDriver. Вскоре вы будете использовать его для реализации логики извлечения данных.
Шаг 2. Подключение к целевой веб-странице.
Вот как выглядит URL страницы акций Yahoo Finance:
https://finance.yahoo.com/quote/AMZNКак видите, это динамический URL, который меняется в зависимости от тикера. Если вы не знакомы с этим понятием, то это краткая аббревиатура, используемая для уникальной идентификации акций, торгуемых на фондовом рынке. Например, «AMZN» — это тикер акций Amazon.
Давайте изменим скрипт, чтобы тикер читался из аргумента командной строки.
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'sys — это стандартная библиотека Python, которая обеспечивает доступ к аргументам командной строки. Не забывайте, что аргумент с индексом 0 — это имя вашего скрипта. Таким образом, вы должны адресовать аргумент с индексом 1.
После считывания тикера из CLI он используется в f-строке для создания целевого URL для парсинга.
Например, предположим, что парсер запущен с тикером Tesla «TSLA:».
python scraper.py TSLA
URL будет содержать:
https://finance.yahoo.com/quote/TSLAЕсли вы забудете символ тикера в CLI, программа завершится ошибкой:
Ticker symbol CLI argument missing!Перед открытием любой страницы в Selenium рекомендуем установить размер окна, чтобы был показан каждый элемент:
driver.set_window_size(1920, 1080)Теперь вы можете использовать Selenium для подключения к целевой странице с помощью:
driver.get(url)Функция get() дает браузеру указание посетить нужную страницу.
Вот как должен выглядеть ваш скрипт парсинга Yahoo Finance:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# set up the window size of the controlled browser
driver.set_window_size(1920, 1080)
# visit the target page
driver.get(url)
# scraping logic...
# close the browser and free up the resources
driver.quit()Если вы запустите его, он откроет это окно на долю секунды и после завершит работу:

Запуск браузера с пользовательским интерфейсом полезен для отладки путем отслеживания действий парсера на веб-странице. В то же время это требует ресурсы. Чтобы избежать этого, настройте Chrome для работы в автономном режиме с помощью:
from selenium.webdriver.chrome.options import Options
# ...
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)Теперь управляемый браузер будет запускаться без пользовательского интерфейса.
Шаг 3. Проверка целевой страницы
Если вы хотите структурировать эффективную стратегию интеллектуального анализа данных, сначала необходимо проанализировать целевую веб-страницу. Откройте браузер и страницу акций Yahoo.
Если вы находитесь в Европе, вы сначала увидите окно с просьбой принять файлы cookie:

Чтобы закрыть его и продолжить посещение страницы, необходимо нажать «Принять все» или «Отклонить все». Щелкните правой кнопкой мыши на первую кнопку и выберите параметр «Проверить», чтобы открыть DevTools вашего браузера:

Здесь вы заметите, что можете выбрать эту кнопку с помощью следующего селектора CSS:
.consent-overlay .accept-allИспользуйте эти строки для работы с модулем согласия в Selenium:
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the "Accept all" button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')WebDriverWait позволяет дождаться появления ожидаемого состояния на странице. Если в течение указанного времени ожидания ничего не происходит, появляется исключение TimeoutException. Поскольку наложение cookie отображается только тогда, когда ваш IP-адрес является европейским, вы можете обработать исключение с помощью инструкции try-catch. Так скрипт будет продолжать работать, когда модальное окно согласия отсутствует.
Чтобы скрипт заработал, вам нужно добавить следующие импорты:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutExceptionТеперь продолжайте просматривать целевой сайт в DevTools и знакомьтесь с его DOM-структурой.
Шаг 4: Извлечение данных об акциях
Как вы могли заметить в шаге №3, некоторые из наиболее интересных сведений находятся в этом разделе:

Проверьте элемент индикатора цены HTML:
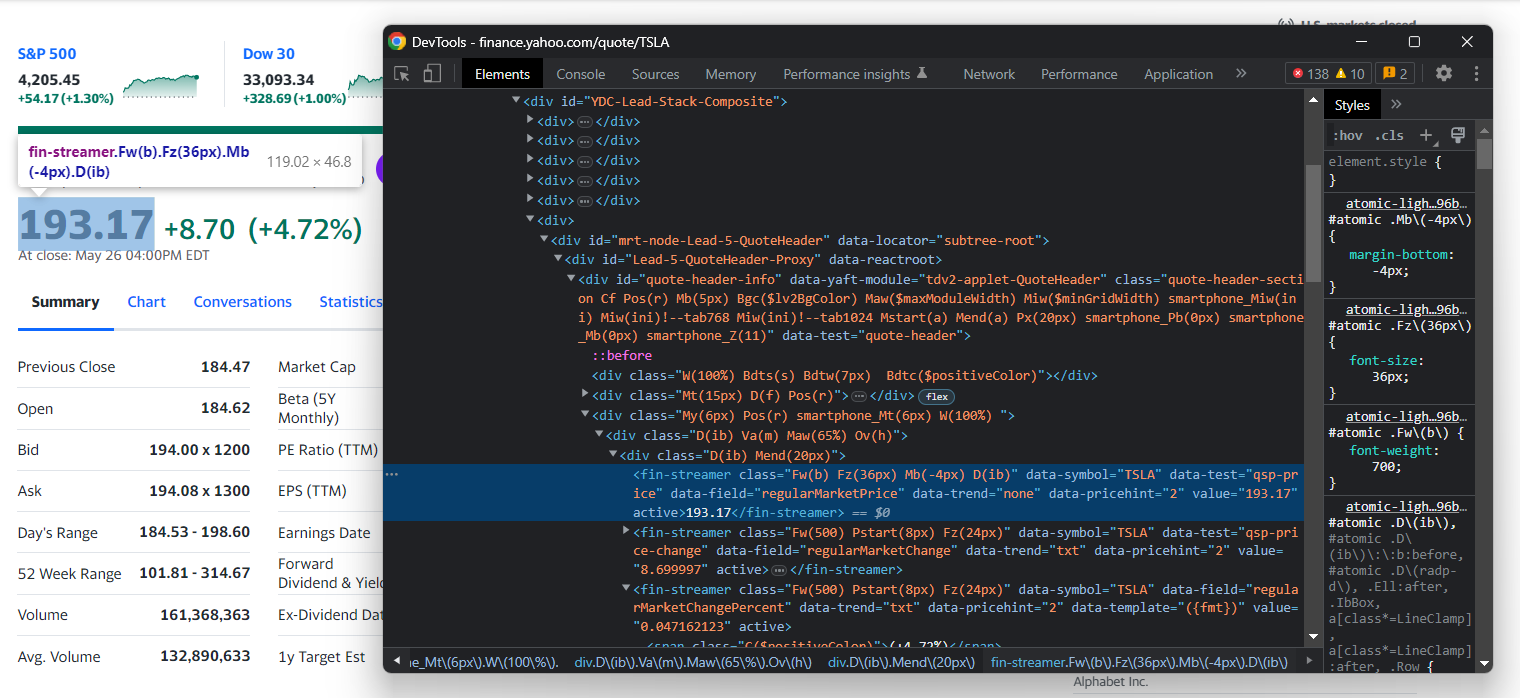
Учтите, что классы CSS бесполезны для определения правильных селекторов в Yahoo Finance. Кажется, что они следуют специальному синтаксису для рамки стиля. Лучше сосредоточьтесь на других атрибутах HTML. Например, вы можете получить цену акции с помощью селектора CSS:
[data-symbol="TSLA"][data-field="regularMarketPrice"]Следуя аналогичному подходу, извлеките все данные об акциях из ценовых индикаторов с помощью:
regular_market_price = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')\
.text
regular_market_change = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')\
.text
regular_market_change_percent = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')\
.text\
.replace('(', '').replace(')', '')
post_market_price = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')\
.text
post_market_change = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')\
.text
post_market_change_percent = driver\
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')\
.text\
.replace('(', '').replace(')', '')
После выбора элемента HTML с помощью определенной стратегии селектора CSS вы можете извлечь его содержимое с помощью текстового поля. Поскольку поля процентов включают круглые скобки, они удаляются с помощью replace().
Добавьте их в фондовый словарь и распечатайте, чтобы убедиться, что процесс парсинга финансовых данных работает должным образом:
# initialize the dictionary
stock = {}
# stock price scraping logic omitted for brevity...
# add the scraped data to the dictionary
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
print(stock)Запустите скрипт на ценной бумаге, которую вы хотите парсить. Вы должны увидеть подобное:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}Другую полезную информацию вы можете найти в таблице #quote-summary:

В этом случае вы можете извлечь каждое поле данных благодаря атрибуту data-test, как в приведенном ниже селекторе CSS:
#quote-summary [data-test="PREV_CLOSE-value"]Парсите их все с помощью:
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').textЗатем добавьте их в stock:
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_estОтлично! Вы только что выполнили финансовый анализ веб-страниц с помощью Python!
Шаг 5: Парсинг нескольких акций
Диверсифицированный инвестиционный портфель состоит из нескольких ценных бумаг. Чтобы получить данные по всем из них, необходимо расширить скрипт для поиска нескольких тикеров.
Во-первых, заключите логику парсинга в функцию:
def scrape_stock(driver, ticker_symbol):
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
driver.get(url)
# deal with the consent modal...
# initialize the stock dictionary with the
# ticker symbol
stock = { 'ticker': ticker_symbol }
# scraping the desired data and populate
# the stock dictionary...
return stockЗатем переберите итерации тикера CLI и примените функцию парсинга:
if len(sys.argv) <= 1:
print('Ticker symbol CLI arguments missing!')
sys.exit(2)
# initialize a Chrome instance with the right
# configs
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))В конце цикла for список акций словарей Python будет содержать все данные фондового рынка.
Шаг 6. Экспорт полученных данных в CSV
Вы можете экспортировать собранные данные в CSV, написав всего несколько строк кода:
import csv
# ...
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)Этот фрагмент создает файл stocks.csv с помощью open(), инициализирует строку заголовка и заполняет его. В частности, DictWriter.writerows() преобразует каждый словарь в запись CSV и добавляет ее в выходной файл.
Поскольку csv входит в стандартную библиотеку Python, вам даже не нужно устанавливать дополнительную зависимость для достижения желаемой цели.
Вы начали с необработанных данных, содержащихся на веб-странице и получили полуструктурированные данные в файле CSV. Пришло время взглянуть на весь парсер Yahoo Finance.
Шаг 7: Сбор в одном месте
Вот полный файл scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import sys
import csv
def scrape_stock(driver, ticker_symbol):
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# visit the target page
driver.get(url)
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the 'Accept all' button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')
# initialize the dictionary that will contain
# the data collected from the target page
stock = { 'ticker': ticker_symbol }
# scraping the stock data from the price indicators
regular_market_price = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]') \
.text
regular_market_change = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]') \
.text
regular_market_change_percent = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]') \
.text \
.replace('(', '').replace(')', '')
post_market_price = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]') \
.text
post_market_change = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]') \
.text
post_market_change_percent = driver \
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]') \
.text \
.replace('(', '').replace(')', '')
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
# scraping the stock data from the "Summary" table
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR,
'#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est
return stock
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
options = Options()
options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# set up the window size of the controlled browser
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))
# close the browser and free up the resources
driver.quit()
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)Менее чем за 150 строк кода вы создали полнофункциональный парсер для извлечения данных из Yahoo Finance.
Запустите его на целевых акциях, как показано в примере ниже:
python scraper.py TSLA AMZN AAPL META NFLX GOOGВ конце процесса парсинга этот файл stocks.csv появится в корневой папке вашего проекта:

Подведем итоги
В этом руководстве вы узнали, почему Yahoo Finance является одним из лучших финансовых порталов в Интернете и как извлекать из него данные. В частности, вы увидели, как создать парсер Python, который может извлекать из него данные об акциях. Как вы могли заметить, это не сложно и занимает всего несколько строк кода.
В то же время Yahoo Finance — это динамичный сайт, который в значительной степени зависит от JavaScript. При работе с такими сайтами традиционного подхода, основанного на библиотеке HTTP и парсере HTML, недостаточно. Кроме того, такие популярные сайты, как правило, внедряют передовые технологии защиты данных. Чтобы парсить их, вам нужен управляемый браузер, который автоматически может обрабатывать CAPTCHA, отпечатки пальцев, автоматические повторные попытки и многое другое для вас. Это именно то, что представляет собой наше новое решение – Scraping Browser!
Кредитная карта не требуется
Вы не хотите заниматься парсингом, но интересуетесь финансовыми данными? Изучите наш список наборов данных.

