

Обучение модели искусственного интеллекта заключается в том, чтобы научить ее распознавать закономерности в данных для принятия решений. Тонкая настройка – это стратегия, которая позволяет адаптировать модели, обученные на больших наборах данных, таких как OpenAI GPT-4, к меньшим, специфическим для конкретной задачи наборам данных путем продолжения процесса обучения.
В следующих разделах мы более подробно рассмотрим процесс обучения пользовательской модели ИИ с помощью тонкой настройки OpenAI и проведем вас через каждый этап процесса тонкой настройки.
Понимание ИИ и обучение моделей
Искусственный интеллект (ИИ) предполагает разработку систем, способных решать задачи, которые обычно требуют человеческого интеллекта, такие как обучение, решение проблем и принятие решений. Модель ИИ, по своей сути, представляет собой набор алгоритмов, которые делают прогнозы на основе входных данных. Машинное обучение (ML), подмножество ИИ, позволяет машинам обучаться на основе данных и автономно повышать производительность.
Модели ИИ учатся подобно ребенку, различающему кошек и собак: наблюдают за особенностями, делают предположения, исправляют ошибки и повторяют попытки. Этот процесс, известный как обучение модели, включает в себя обработку моделью входных данных, анализ и обработку закономерностей, а также использование этих знаний для составления прогнозов. Эффективность модели оценивается путем сравнения ее выходных данных с ожидаемым результатом, и в нее вносятся коррективы для повышения эффективности. При достаточном обучении набор алгоритмов, входящих в модель, будет представлять собой точный математический предсказатель для конкретной ситуации, способный работать с различными вариациями входных данных.
Обучение модели с нуля предполагает обучение модели изучению закономерностей в данных без каких-либо предварительных знаний. Это требует большого количества данных и вычислительных ресурсов, и модель может не справиться с задачей при ограниченном количестве данных.
Тонкая настройка, с другой стороны, начинается с предварительно обученной модели, которая изучила общие закономерности на большом наборе данных. Затем модель проходит дальнейшее обучение на меньшем, конкретном наборе данных, что позволяет ей применить ранее полученные знания к новой задаче, что часто приводит к улучшению производительности при меньшем объеме данных и вычислительных ресурсов. Тонкая настройка особенно полезна, когда набор данных для конкретной задачи относительно невелик.
Подготовка к тонкой настройке
Тонкая настройка существующей модели с дополнительным обучением на курируемом наборе данных может показаться привлекательным вариантом по сравнению с созданием и обучением модели ИИ с нуля. Однако успех процесса тонкой настройки зависит от нескольких ключевых факторов.
Выбор правильной модели
При выборе базовой модели для тонкой настройки учитывайте следующее:
Согласование задач: Важно четко определить круг задач и ожидаемую функциональность модели. Выбирайте модели, которые отлично справляются с задачами, схожими с вашей, поскольку расхождение между исходной и целевой задачами в процессе тонкой настройки может привести к снижению производительности. Например, для задач генерации текста может подойти GPT-3, а для задач классификации текста лучше использовать BERT или RoBERTa.
Размер и сложность модели: Сбалансируйте производительность и эффективность, поскольку, хотя большие модели лучше передают сложные паттерны, они требуют больше ресурсов.
Метрики оценки: Выберите метрики оценки, соответствующие вашей задаче. Например, точность может быть важна для классификации, в то время как BLEU или ROUGE могут быть полезны для задач генерации языка.
Сообщество и ресурсы: Выбирайте модели с большим сообществом и обширными ресурсами для устранения неполадок и внедрения. Отдавайте предпочтение моделям с четкими рекомендациями по тонкой настройке для вашей задачи и ищите авторитетные источники для контрольных точек предварительно обученных моделей.
Сбор и подготовка данных
При тонкой настройке качество и разнообразие данных могут существенно повлиять на производительность модели. Вот некоторые ключевые соображения:
Необходимые типы данных: Тип данных зависит от конкретной задачи и от того, на каких данных была предварительно обучена модель. Для задач NLP обычно нужны текстовые данные из таких источников, как книги, статьи, посты в социальных сетях или стенограммы речи. Для сбора данных используйте такие методы, как веб-скраппинг, опросы или API от платформ социальных сетей. Например, веб-скраппинг с помощью ИИ может быть особенно полезен, когда вам нужен большой объем разнообразных и актуальных данных.
Очистка и аннотирование данных: Очистка данных включает в себя удаление неактуальных данных, обработку отсутствующих или противоречивых данных, а также нормализацию. Аннотирование включает в себя маркировку данных, чтобы модель могла учиться на их основе. Использование автоматизированных инструментов, таких как Bright data, позволяет упростить эти процессы и повысить эффективность.
Включение разнообразных и репрезентативных наборов данных: При тонкой настройке модели разнообразные и репрезентативные наборы данных обеспечивают обучение модели с разных точек зрения, что приводит к более обобщенным и надежным прогнозам. Например, если вы настраиваете модель анализа настроений для отзывов о фильмах, в ваш набор данных должны входить отзывы о самых разных фильмах, жанрах и настроениях, что отражает распределение классов в реальном мире.
Настройка среды обучения
Убедитесь, что у вас есть необходимое оборудование и программное обеспечение для выбранной модели и фреймворка ИИ. Например, большие языковые модели (LLM) часто требуют значительной вычислительной мощности, которую обычно обеспечивают графические процессоры.
Для обучения моделей ИИ обычно используются такие фреймворки, как TensorFlow или PyTorch. Установка соответствующих библиотек и инструментов, а также любых дополнительных зависимостей необходима для беспрепятственной интеграции в рабочий процесс обучения. Например, такие инструменты, как OpenAI API, могут понадобиться для тонкой настройки конкретных моделей, разработанных OpenAI.
Процесс тонкой настройки
Разобравшись с основами тонкой настройки, давайте рассмотрим ее применение в обработке естественного языка.
Я буду использовать API OpenAI для тонкой настройки предварительно обученной модели. В настоящее время тонкая настройка возможна для таких моделей, как gpt-3.5-turbo-0125 (рекомендуется), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002 и экспериментальная gpt-4-0613. Тонкая настройка GPT-4 находится в экспериментальной фазе, и желающие могут запросить доступ к ней в пользовательском интерфейсе тонкой настройки.
1. Подготовка массива данных
Согласно исследованию, было обнаружено, что GPT-3.5 не хватает аналитического мышления. Поэтому давайте попробуем доработать модель gpt-3.5-turbo, чтобы повысить ее аналитическое мышление, используя набор данных вопросов по аналитическому мышлению из вступительного теста на юридический факультет (AR-LSAT), выпущенного в 2022 году. Общедоступный набор данных можно найти здесь.
Качество тонкой настройки модели напрямую зависит от данных, используемых для тонкой настройки. Каждый пример в наборе данных должен представлять собой беседу, отформатированную в соответствии с OpenAI’s Chat Completions API, со списком сообщений, где каждое сообщение имеет роль, содержание и необязательное имя, и хранится в виде JSONL-файла.
Необходимый формат разговорного чата для тонкой настройки gpt-3.5-turboisвыглядит следующим образом:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
В этом формате "сообщения" – это список сообщений, образующих диалог между тремя "ролями": системой, пользователем и помощником. "Содержание" роли "система" должно определять поведение тонко настроенной системы.
Ниже приведен пример форматирования, взятый из набора данных AR-LSAT, который мы будем использовать в этом руководстве:

Вот основные соображения при создании набора данных:
- Страница с ценами OpenAI
- Тетрадь для подсчета жетонов
- Скрипт Python
2. Генерация ключа API и установка библиотеки OpenAI
Для тонкой настройки модели OpenAI наличие аккаунта разработчика OpenAI с достаточным кредитным балансом является обязательным.
Чтобы сгенерировать ключ API и установить библиотеку OpenAI, выполните следующие действия:
1. Зарегистрируйтесь на официальном сайте OpenAI.
2. Чтобы включить тонкую настройку, пополните кредитный баланс на вкладке “Биллинг” в разделе “Настройки”.

3. Нажмите на значок профиля пользователя в левом верхнем углу и выберите “Ключи API”, чтобы перейти на страницу создания ключа.

4. Сгенерируйте новый секретный ключ, указав его имя.

5. Установите библиотеку Python OpenAI для тонкой настройки.
pip install openai
6. Используйте библиотеку os для установки токена в качестве переменной окружения и установления связи с API.
import os
from openai import OpenAI
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = 'The key generated in step 4'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. Загрузка учебных и проверочных файлов
После проверки данных загрузите файлы с помощью API Files для тонкой настройки заданий.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
Уникальные идентификаторы данных для обучения и проверки отображаются после успешного выполнения.

4. Создание задания на тонкую настройку
После загрузки файлов создайте задание на тонкую настройку через пользовательский интерфейс или программно.
Вот как инициировать задание по тонкой настройке с помощью OpenAI SDK:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model: имя модели для тонкой настройки(gpt-3.5-turbo,babbage-002,davinci-002или существующая модель с тонкой настройкой).training_fileиvalidation_file: идентификаторы файлов, полученные при их загрузке.n_epochs,batch_sizeиlearning_rate_multiplier: Гиперпараметры, которые можно настраивать.
Для установки дополнительных параметров тонкой настройки обратитесь к спецификации API для тонкой настройки.
Приведенный выше код генерирует следующую информацию для идентификатора задания (`ftjob-0EVPunnseZ6Xnd0oGcnWBZA7`):

На выполнение задания по тонкой настройке может потребоваться время. Оно может стоять в очереди за другими заданиями, а продолжительность обучения может составлять от нескольких минут до нескольких часов в зависимости от модели и размера набора данных.
По завершении обучения пользователю, инициировавшему задание на тонкую настройку, будет отправлено подтверждение по электронной почте.
Вы можете следить за состоянием задания тонкой настройки через пользовательский интерфейс тонкой настройки:
5. Анализ модели с точной настройкой
Во время обучения OpenAI вычисляет следующие показатели:
- Потери при обучении
- Точность обучающих маркеров
- Потеря валидности
- Точность валидационного маркера
Потери при валидации и точность валидационных маркеров рассчитываются двумя способами: на небольшой партии данных на каждом шаге и на полном валидационном наборе в конце каждой эпохи. Потери при полной валидации и точность токенов при полной валидации являются наиболее точными метриками для отслеживания производительности модели и служат в качестве проверки правильности обучения (потери должны уменьшаться, точность токенов – увеличиваться).
Пока задание тонкой настройки активно, вы можете просматривать эти показатели через
1. Пользовательский интерфейс:
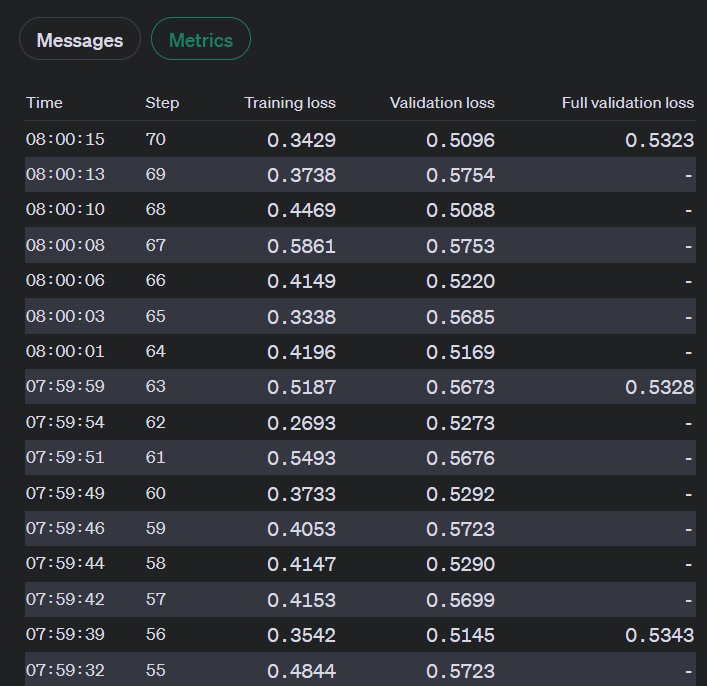
2. API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = ‘jobid you want to monitor’
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(
f'{event.data}'
)
except Exception:
print("Stream interrupted (client disconnected).")
Приведенный выше код выведет потоковые события для задания тонкой настройки, включая количество шагов, потери при обучении, потери при проверке, общее количество шагов и среднюю точность маркера для обучения и проверки:
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. Настройка параметров и набора данных для повышения производительности
Если результаты работы по тонкой настройке не столь хороши, как вы ожидали, рассмотрите следующие способы улучшения производительности:
1. Настройте набор обучающих данных:
- Чтобы уточнить набор обучающих данных, добавьте примеры, которые устраняют недостатки модели, и убедитесь, что распределение ответов в ваших данных соответствует ожидаемому распределению.
- Также важно проверить данные на наличие проблем, которые воспроизводит модель, и убедиться, что ваши примеры содержат всю необходимую информацию для ответа.
- Поддерживайте согласованность данных, созданных несколькими людьми, и стандартизируйте формат всех учебных примеров, чтобы они соответствовали тому, что ожидается при выводе.
- В целом, высококачественные данные более эффективны, чем большое количество низкокачественных.
2. Настройка гиперпараметров:
- OpenAI позволяет задать три гиперпараметра: эпохи, множитель скорости обучения и размер партии.
- Начните со значений по умолчанию, выбранных встроенными функциями в зависимости от размера набора данных, а затем скорректируйте их при необходимости.
- Если модель не следует за обучающими данными, как ожидалось, увеличьте количество эпох.
- Если модель становится менее разнообразной, чем ожидалось, уменьшите количество эпох на 1 или 2.
- Если кажется, что модель не сходится, увеличьте множитель скорости обучения.
7. Использование модели с контрольными точками
В настоящее время OpenAI предоставляет доступ к контрольным точкам для трех последних эпох работы по тонкой настройке. Эти контрольные точки представляют собой полные модели, которые можно использовать для выводов и дальнейшей тонкой настройки.
Чтобы получить доступ к этим контрольным точкам, дождитесь успешного выполнения задания, а затем запросите конечную точку checkpoints с идентификатором задания тонкой настройки. В каждом объекте контрольной точки будет заполнено поле fine_tuned_model_checkpoint с именем контрольной точки модели. Вы также можете получить имя модели контрольной точки через пользовательский интерфейс тонкой настройки
Вы можете проверить результаты модели контрольной точки, выполнив запросы с подсказкой и именем модели с помощью функции openai.chat.completions.create():
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five studentsu2014Jiang, Kramer, Lopez, Megregian, and O'Neillu2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?nA. LopeznB. O'NeillnC. Jiang, LopeznD. Kramer, O'NeillnE. Lopez, MegregiannAnswer:"}
]
)
print(completion.choices[0].message)
Результат, полученный из словаря ответов, следующий:

Вы также можете сравнить точно настроенную модель с другими моделями на игровой площадке OpenAI, как показано ниже:

Советы и лучшие практики
Для успешной настройки воспользуйтесь следующими советами:
Качество данных: Убедитесь, что ваши данные по конкретной задаче чисты, разнообразны и репрезентативны, чтобы избежать чрезмерной подгонки, когда модель хорошо работает на обучающих данных, но плохо – на невидимых.
Выбор гиперпараметров: Выберите подходящие гиперпараметры, чтобы избежать медленной сходимости или неоптимальной производительности. Это может быть сложной и трудоемкой задачей, но имеет решающее значение для эффективного обучения.
Управление ресурсами: Помните, что тонкая настройка больших моделей требует значительных вычислительных ресурсов и времени.
Избегайте подводных камней
Переоценка и недооценка: Сбалансируйте сложность модели и объем обучения, чтобы избежать чрезмерной подгонки (высокая дисперсия) и недостаточной подгонки (высокая погрешность).
Катастрофическое забывание: В процессе тонкой настройки модель может забыть ранее полученные общие знания. Чтобы избежать этого, регулярно оценивайте работу модели на различных задачах.
Чувствительность к сдвигу домена: Если данные тонкой настройки значительно отличаются от данных предварительного обучения, вы можете столкнуться с проблемой смещения домена. Используйте методы адаптации домена, чтобы преодолеть этот разрыв.
Сохранение и повторное использование моделей
После обучения сохраните состояние модели, чтобы использовать ее в дальнейшем. Сюда входят параметры модели и любое состояние оптимизатора, который использовался. Это позволит вам возобновить обучение позже из того же состояния.
Этические соображения
Усиление предвзятости: Предварительно обученные модели могут унаследовать предвзятость, которая может усилиться при тонкой настройке. Всегда старайтесь выбирать предварительно обученные модели, проверенные на предвзятость и справедливость, если требуются беспристрастные прогнозы.
Непреднамеренные результаты: Тонко настроенные модели могут генерировать правдоподобные, но неверные результаты. Реализуйте надежные механизмы постобработки и проверки, чтобы справиться с этим.
Дрейф модели: Производительность модели может ухудшиться со временем из-за изменений в окружающей среде или распределении данных. Регулярно следите за производительностью модели и при необходимости проводите повторную настройку.
Продвинутые техники и дальнейшее обучение
Передовые методы тонкой настройки LLM включают адаптацию с низким рангом (LoRA) и квантованную адаптацию (QLoRA), которые позволяют снизить вычислительные и финансовые затраты при сохранении производительности. Parameter Efficient Fine Tuning (PEFT) эффективно адаптирует модели с минимальными обучаемыми параметрами. DeepSpeed и ZeRO оптимизируют использование памяти для крупномасштабного обучения. Эти методы решают такие проблемы, как чрезмерная подгонка, катастрофическое забывание и чувствительность к сдвигу домена, повышая эффективность и результативность тонкой настройки LLM.
Помимо тонкой настройки, существуют и другие передовые методы обучения, такие как трансферное обучение и обучение с подкреплением. Трансферное обучение предполагает применение знаний, полученных при решении одной задачи, к другой, связанной с ней, а обучение с подкреплением – это тип машинного обучения, при котором агент учится принимать решения, совершая действия в окружающей среде для получения максимального вознаграждения.
Для тех, кто хочет глубже погрузиться в обучение моделей ИИ, могут быть полезны следующие ресурсы:
- Внимание – это все, что вам нужно” Ашиш Васвани и др.
- Книга “Глубокое обучение” Яна Гудфеллоу, Йошуа Бенгио и Аарона Курвиля
- Книга “Обработка речи и языка” Даниэля Юрафски и Джеймса Х. Мартина
- Различные способы подготовки магистров
- Освоение техники LLM: Тренинг
- Курс НЛП от “Обнимая лицо
Заключение
Обучение модели искусственного интеллекта – это процесс, требующий значительного количества высококачественных данных. Хотя определение проблемы, выбор модели и ее доработка в ходе итераций очень важны, истинным отличием является качество и объем используемых данных. Вместо того чтобы создавать и поддерживать веб-скреперы, вы можете упростить сбор данных, используя готовые или пользовательские наборы данных, доступные на платформе Bright Data.
С помощью Dataset Marketplace вы можете получить доступ к проверенным, готовым наборам данных с популярных веб-сайтов или создать собственные наборы данных, отвечающие вашим конкретным потребностям, используя автоматизированную платформу. Таким образом, вы можете сосредоточиться на эффективном обучении своих моделей с использованием точных и соответствующих требованиям данных, что позволит получить более быстрые и надежные результаты в различных отраслях.
Ознакомьтесь с решениями Bright Data для работы с наборами данных и легко интегрируйте их в свой рабочий процесс для беспрепятственного сбора данных.
Зарегистрируйтесь сейчас и начните бесплатную пробную версию инфраструктуры скраппинга Bright Data, включая бесплатные образцы наборов данных.
Кредитная карта не требуется


